

Post 13 - Introducing VeLO - A Leap Towards Auto-Tuning Neural Network Optimization
Tired of babysitting hyperparameters for endless hours? Frustrated with uncertain results? Meet VeLO: the optimizer’s optimizer. It’s like having a personal trainer for your neural network, but without the sweat and tears :D!
1. What are Optimizers in Deep Learning
Deep learning is the subfield of machine learning which is used to perform complex tasks such as speech recognition, text classification, etc. The deep learning model consists of an activation function, input, output, hidden layers, loss function, etc. All deep learning algorithms try to generalize the data using an algorithm and try to make predictions on unseen data. We need an algorithm that maps the examples of inputs to that of the outputs along with an optimization algorithm. An optimization algorithm finds the value of the parameters (weights) that minimize the error when mapping inputs to outputs.
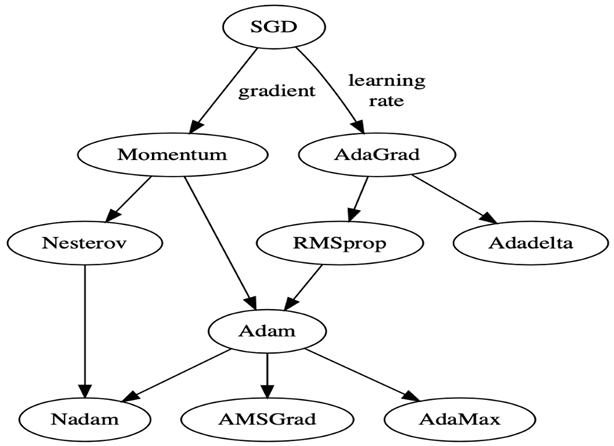
While training the deep learning optimizers model, modify each epoch’s weights and minimize the loss function. An optimizer is a function or an algorithm that adjusts the attributes of the neural network, such as weights and learning rates. Thus, it helps in reducing the overall loss and improving accuracy. The problem of choosing the right weights for the model is a daunting task, as a deep learning model generally consists of millions of parameters. It raises the need to choose a suitable optimization algorithm for your application. Hence understanding these machine learning algorithms is necessary for data scientists before having a deep dive into the field. You can use different optimizers in the machine learning model to change your weights and learning rate. However, choosing the best optimizer depends upon the application.
In a nutshell, Optimizer Algorithms are optimization method that helps improve a deep learning model’s performance. These optimization algorithms or optimizers widely affect the accuracy and speed training of the deep learning model. There are various optimizers available in the deep learning model, such as Stochastic Gradient Descent (SGD), Adam, RMSprop, Adagrad, Adadelta, Adamax, Nadam, etc.
This post will not deep dive into the details of Optimizers. If you want to know more about Optimizers, I recommend you to read A Comprehensive Guide on Optimizers in Deep Learning of Analytics Vidhya.
2. What is Hyparameter Optimization
Machine Learning models are composed of two different types of parameters:
- Hyperparameters = are all the parameters which can be arbitrarily set by the user before starting training (eg. number of estimators in Random Forest).
- Model parameters = are instead learned during the model training (eg. weights in Neural Networks, Linear Regression).
The model parameters define how to use input data to get the desired output and are learned at training time. Instead, Hyperparameters determine how our model is structured in the first place.
Machine Learning models tuning is a type of optimization problem. We have a set of hyperparameters and we aim to find the right combination of their values which can help us to find either the minimum (eg. loss) or the maximum (eg. accuracy) of a function (Figure 1).
So in a nutshell, hyperparameter optimization or tuning is the problem of choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a parameter whose value is used to control the learning process. By contrast, the values of other parameters (typically node weights) are learned.
Hyperparameter optimization can be a time-consuming process, especially when dealing with complex models and large datasets. The time required for hyperparameter optimization depends on several factors:
-
Search Space Size: The larger the search space (i.e., the range of hyperparameter values to explore), the more time it will take to perform an exhaustive search. Grid search, for example, explores all combinations of hyperparameters, which can be computationally expensive.
-
Model Complexity: Training complex models with many layers and parameters may take longer to converge and evaluate during hyperparameter optimization compared to simpler models.
-
Data Size: The size of the training dataset can also impact the time required for hyperparameter optimization. Larger datasets may require more time to process and train models.
-
Computing Resources: The availability of computational resources (e.g., CPU, GPU, or multiple GPUs) also affects the time required for hyperparameter optimization. Utilizing more powerful hardware can speed up the process.
-
Cross-Validation: If cross-validation is used for hyperparameter evaluation, the training process needs to be repeated multiple times (k times for k-fold cross-validation), adding to the overall time.
-
Optimization Algorithm: The choice of the hyperparameter optimization algorithm can impact the time required. Bayesian optimization, for example, is more efficient in exploring the search space compared to exhaustive grid search.
2. VeLO Paper Explained
Click here to read the full paper on my platform.
What’s new: Luke Metz, James Harrison, and colleagues at Google devised VeLO, a system designed to act as a fully tuned optimizer. It uses a neural network to compute the target network’s updates.
Key insight: Machine learning engineers typically find the best values of optimizer hyperparameters such as learning rate, learning rate schedule, and weight decay by trial and error. This can be cumbersome, since it requires training the target network repeatedly using different values. In the proposed method, a different neural network takes the target network’s gradients, weights, and current training step and outputs its weight updates — no hyperparameters needed.

-
LSTM-Based Weight Generation: At every time step, an LSTM creates the weights for what we’ll call the optimizer network. This network, in turn, updates the target one.
-
Optimizer Network Training: Instead of backpropagation, the LSTM learns through evolution, generating numerous LSTMs with random differences, averaging them based on performance, and iterating the process.
-
Testing Various Architectures: The researchers tested VeLO across a multitude of neural networks including vanilla, convolutional, recurrent, transformers, etc., and on different tasks such as image classification and text generation.
-
Optimization through Statistics: Various statistics like mean and variance of weights, exponential moving averages of gradients, training loss value, etc., were taken into account for the optimization.
3. VeLO Limitations
Yes, but: While VeLO brings an innovative leap in optimization, it’s not without its stumbling blocks. It falters in scenarios where traditional optimizers usually demand the most manual tuning. Specifically, when dealing with models exceeding 500 million parameters and requiring over 200,000 training steps, VeLO’s performance diminishes. The authors attribute this shortcoming to VeLO’s limited exposure during training to such large-scale networks and extended training runs.
Why VeLO Still Matters: Despite these challenges, VeLO’s influence on the AI landscape is undeniable. It injects efficiency into model development by cutting down the need to experiment with hyperparameters and expediting the optimization process itself. Unlike conventional optimizers, VeLO leverages a broad spectrum of statistics related to the target network’s real-time training. This enriched perspective enables VeLO to craft updates that steer models closer to optimal solutions more rapidly.
4. Conclusion: The Future of Optimization
VeLO presents a significant stride towards auto-tuning neural network optimization. By accelerating model development and computing updates that drive models closer to optimal solutions, it offers a new horizon in the AI field.
While it may have overfit to the specific task sizes the researchers tested, VeLO paves the way for more robust algorithms that can work across larger architectures and extensive training steps.
In a landscape where efficiency is paramount, VeLO stands as a testament to the relentless pursuit of innovation, contributing to the future where even optimizers could be optimized by neural networks.
4. References for this post
- VeLO: Training Versatile Learned Optimizers by Scaling Up - Paper Arxiv
- VeLO - Optimizer Without Hyperparameters - DeepLearning.AI
