

Post 11 - Kỹ thuật Active Learning (Phần 1)
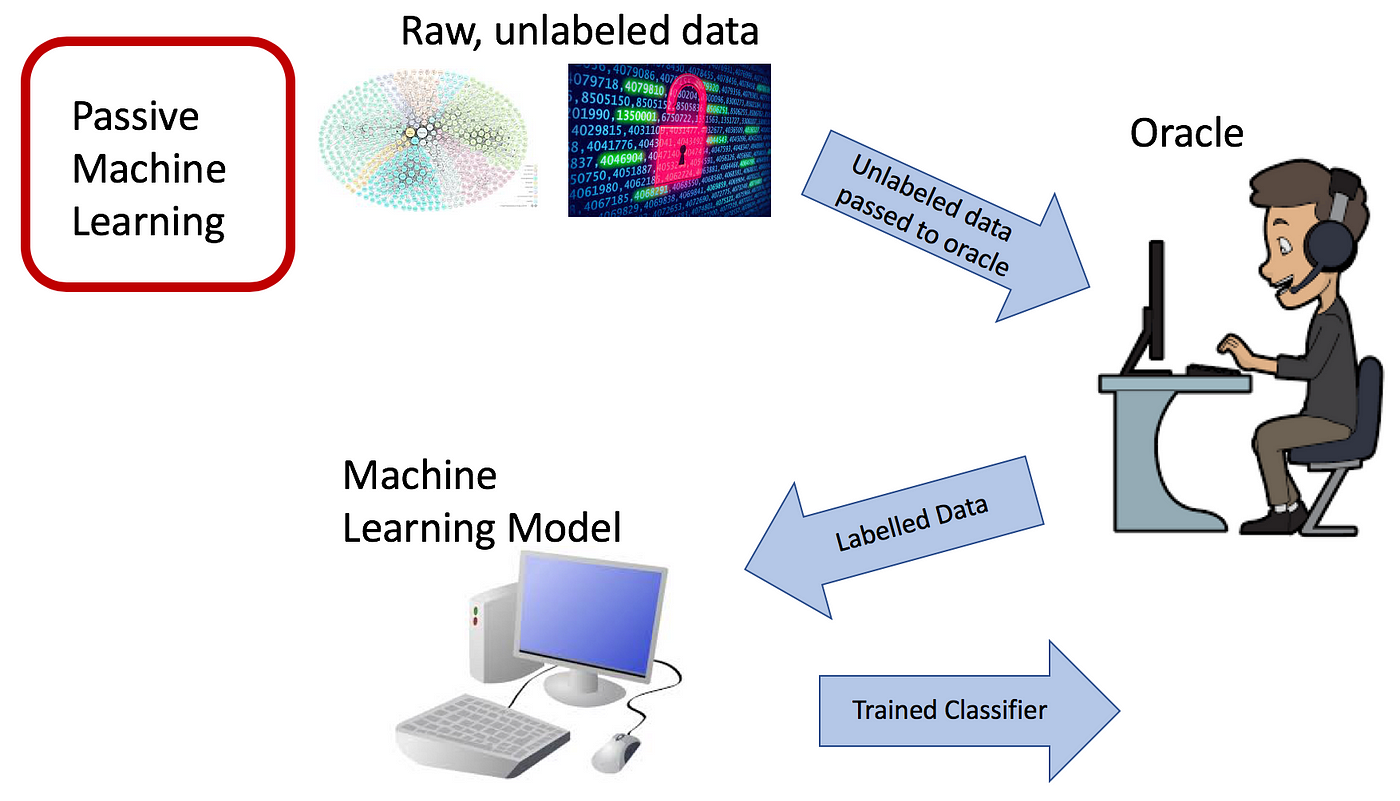
1. Active Learning là gì?
Active Learning là một phương pháp học máy (machine learning) trong đó mô hình được huấn luyện để chủ động tương tác và học từ các dữ liệu mới một cách thông minh hơn. Thay vì yêu cầu một lượng lớn các dữ liệu được gán nhãn trước để huấn luyện mô hình, Active Learning sử dụng các thuật toán để chọn các mẫu dữ liệu tiềm năng để được gán nhãn và sử dụng chúng để cải thiện mô hình.
Nghe qua định nghĩa thôi, là ta có thể thấy rằng Active Learning một kĩ thuật rất hữu ích trong dự án thực tế với trường hợp chi phí gán nhãn dữ liệu hạn chế. Tiếp theo ta sẽ đi vào tìm hiểu các nội dung trong phần 1 của chuỗi chủ đề này:
- Tầm quan trọng của dữ liệu có nhãn đối với một bài toán học máy
- Khái niệm cơ bản về Active Learning - một phương pháp hữu ích giúp định nghĩa các dữ liệu nào mà mô hình cần gán nhãn
- Các thuật toán Active Learning cơ bản
Bài viết có sự tham khảo từ nhiều nguồn và khóa Active Learning của team Sun* AI Research Team. Rất cảm ơn team đã giới thiệu về kỹ thuật này.
2. Dữ liệu quan trọng như thế nào?
Dữ liệu là yếu tố cực kỳ quan trọng trong trí tuệ nhân tạo (AI). Một mô hình AI cần phải được huấn luyện trên các dữ liệu đầu vào để có thể học và hiểu các quy luật hoặc mối quan hệ giữa các đặc trưng của dữ liệu. Điều này giúp mô hình có thể dự đoán và đưa ra các quyết định dựa trên dữ liệu mới, chưa từng được mô hình thấy trước đó.
Dữ liệu có thể được thu thập bởi chỉnh con người và cung cấp cho các mô hình học máy hoặc với sự phát triển của AI ngày nay, các mô hình đã có thể tự học và tự thu thập dữ liệu. Điều này được thực hiện thông qua các phương pháp học tăng cường và học sâu tự động (self-supervised learning) mà có thể tự động tạo ra các dữ liệu mới để huấn luyện và cải thiện mô hình.
Ví dụ, trong học tăng cường (reinforcement learning), một mô hình AI có thể được huấn luyện để tương tác với môi trường và tự động thu thập dữ liệu thông qua các hoạt động tương tác của nó với môi trường đó. Mô hình sẽ học từ các kết quả của các hành động của nó và điều chỉnh chiến lược để đạt được các mục tiêu đã đề ra.
Hoặc đôi khi ciệc tự động sinh dữ liệu có thể được sử dụng để mở rộng dữ liệu huấn luyện và tăng cường độ đa dạng của dữ liệu. Tuy nhiên, việc sử dụng các dữ liệu được tự động sinh ra cần được thận trọng và đánh giá kỹ lưỡng để đảm bảo chất lượng của dữ liệu.
Nhìn chung, dữ liệu thu thập được cũng phải đáp ứng một số tiêu chí vì dữ liệu “không tốt” có thể dẫn tới mô hình hoạt động không như mong muốn trong thế giới thực. Mình xin được đề cập các tiêu chí cần đảm bảo của dữ liệu trong lĩnh vực BigData:
-
Tính đầy đủ: Dữ liệu trong big data cần bao gồm đủ thông tin để đáp ứng yêu cầu của bài toán. Dữ liệu không nên thiếu hoặc bị lấp đầy các giá trị trống, để tránh ảnh hưởng đến độ chính xác và độ tin cậy của kết quả.
-
Tính đúng đắn: Dữ liệu cần phải được xác nhận là đúng đắn và chính xác. Điều này đòi hỏi kiểm tra và xác minh các giá trị dữ liệu để đảm bảo rằng chúng đáp ứng được các yêu cầu của bài toán.
-
Tính liên tục: Dữ liệu trong big data thường được cập nhật liên tục và không ngừng nghỉ. Điều này đòi hỏi các hệ thống phải có khả năng xử lý dữ liệu liên tục và đáp ứng được nhu cầu của các ứng dụng.
-
Tính đa dạng: Dữ liệu trong big data có thể bao gồm nhiều loại dữ liệu khác nhau, bao gồm cả dữ liệu có cấu trúc và dữ liệu không có cấu trúc. Do đó, các hệ thống phải có khả năng xử lý và phân tích dữ liệu đa dạng.
-
Tính bảo mật: Dữ liệu trong big data thường chứa nhiều thông tin nhạy cảm, do đó cần được bảo vệ và đảm bảo tính riêng tư và an toàn.
-
Tính sẵn sàng: Dữ liệu trong big data phải sẵn sàng và dễ truy cập để có thể được sử dụng khi cần thiết. Điều này đòi hỏi các hệ thống phải có khả năng lưu trữ và quản lý dữ liệu hiệu quả, và đáp ứng được nhu cầu của người dùng.
Vậy quay trở lại gần hơn với chủ đề ngày hôm nay của chúng ta là Active Learning, ta sẽ nói đến một khái niệm nữa liên quan tới dữ liệu là gán nhãn dữ liệu (labeling)
3. Gán nhãn dữ liệu (labeling)
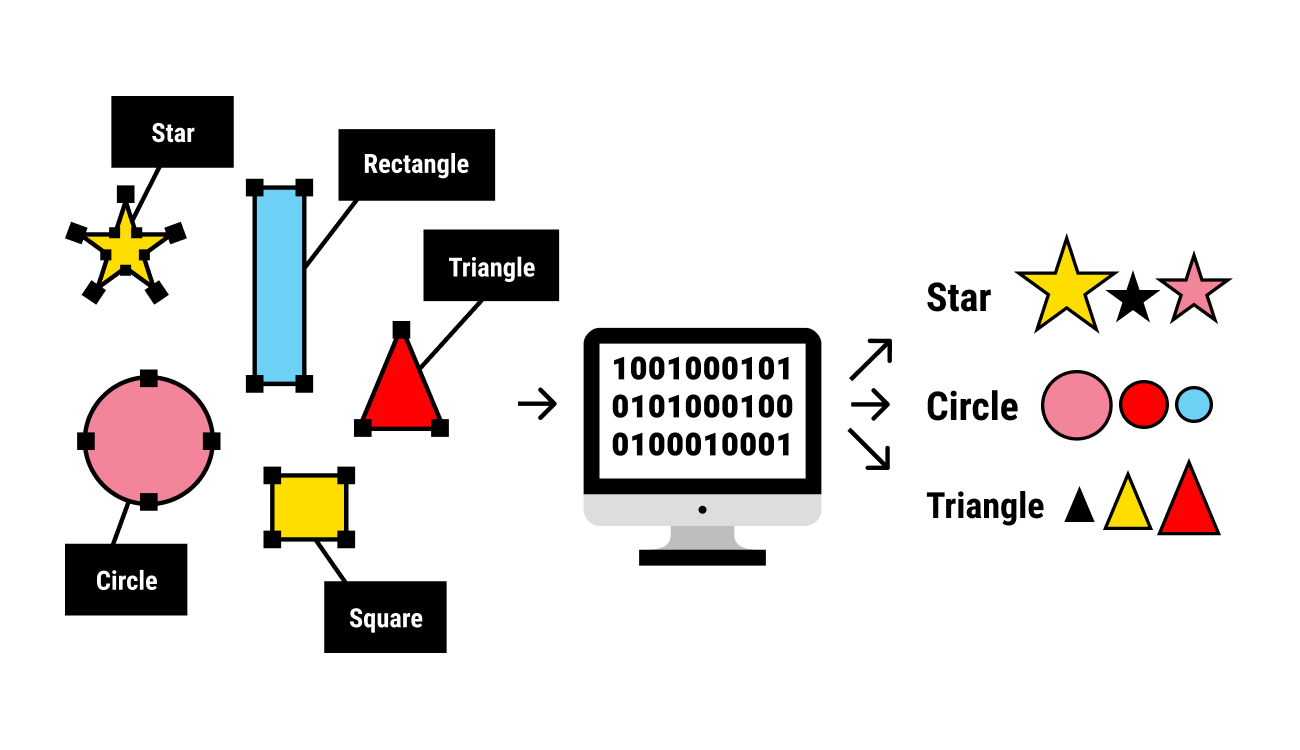
Ta có thể thấy các mô hình học máy được con người xây dựng đều mong muốn giải quyết một bài toán thực trong cuộc sống. Các tác vụ có thể kể đến như phân loại, phát hiện, nhận diện, dự đoán,.. Và đa phần các bài toán đó đều thuộc dạng bài toán học có giám sát (supervised learning) (so với bài toán unsupervised learning).
Đối với bài toán này, yêu cầu của dữ liệu là cần phải được gán nhãn, nghĩa là chúng ta biết kết quả mong muốn cho mỗi mẫu dữ liệu. Một mô hình học có giám sát được huấn luyện bằng cách sử dụng các mẫu dữ liệu trong tập huấn luyện để học cách dự đoán kết quả mong muốn cho các mẫu dữ liệu mới.
Vậy vấn đề ở đây đặt ra là việc gán nhãn dữ liệu đóng vai trò quan trọng trong việc huấn luyện các mô hình máy học để dự đoán, phân loại hoặc tạo ra đầu ra. Ví dụ, trong bài toán phân loại hình ảnh, một mô hình máy học cần biết đâu là hình ảnh của mèo và đâu là hình ảnh của chó. Để làm được điều này, ta cần có một tập dữ liệu được gán nhãn đúng, tức là mỗi hình ảnh đã được xác định là một con mèo hoặc một con chó.
Tuy nhiên, việc gán nhãn dữ liệu thường rất tốn kém, tốn nhiều thời gian và nhân lực, đặc biệt là đối với các bài toán phức tạp và tập dữ liệu lớn. Ngoài ra, việc gán nhãn dữ liệu còn đòi hỏi sự chính xác và độ tin cậy để đảm bảo rằng mô hình được huấn luyện đúng cách và có thể đưa ra dự đoán chính xác trên các dữ liệu mới.
Mặc dù việc tự động hoặc bán tự động gán nhãn dữ liệu đang được nghiên cứu rộng rãi trong lĩnh vực AI để giảm thiểu tác động của con người trong quá trình gán nhãn dữ liệu và tăng tốc quá trình huấn luyện mô hình nhưng đây vẫn là một quá trình đòi hỏi công sức lớn nếu vẫn còn cần sự can thiệp từ con người. Và đó cũng chính là lý do ra đời khái niệm Active Learning hỗ trợ cho quá trình gán nhãn dữ liệu đó. Vậy Active Learning là một phương pháp giúp định nghĩa các mẫu dữ liệu cần thiết cho quá trình gán nhãn (human annotation).
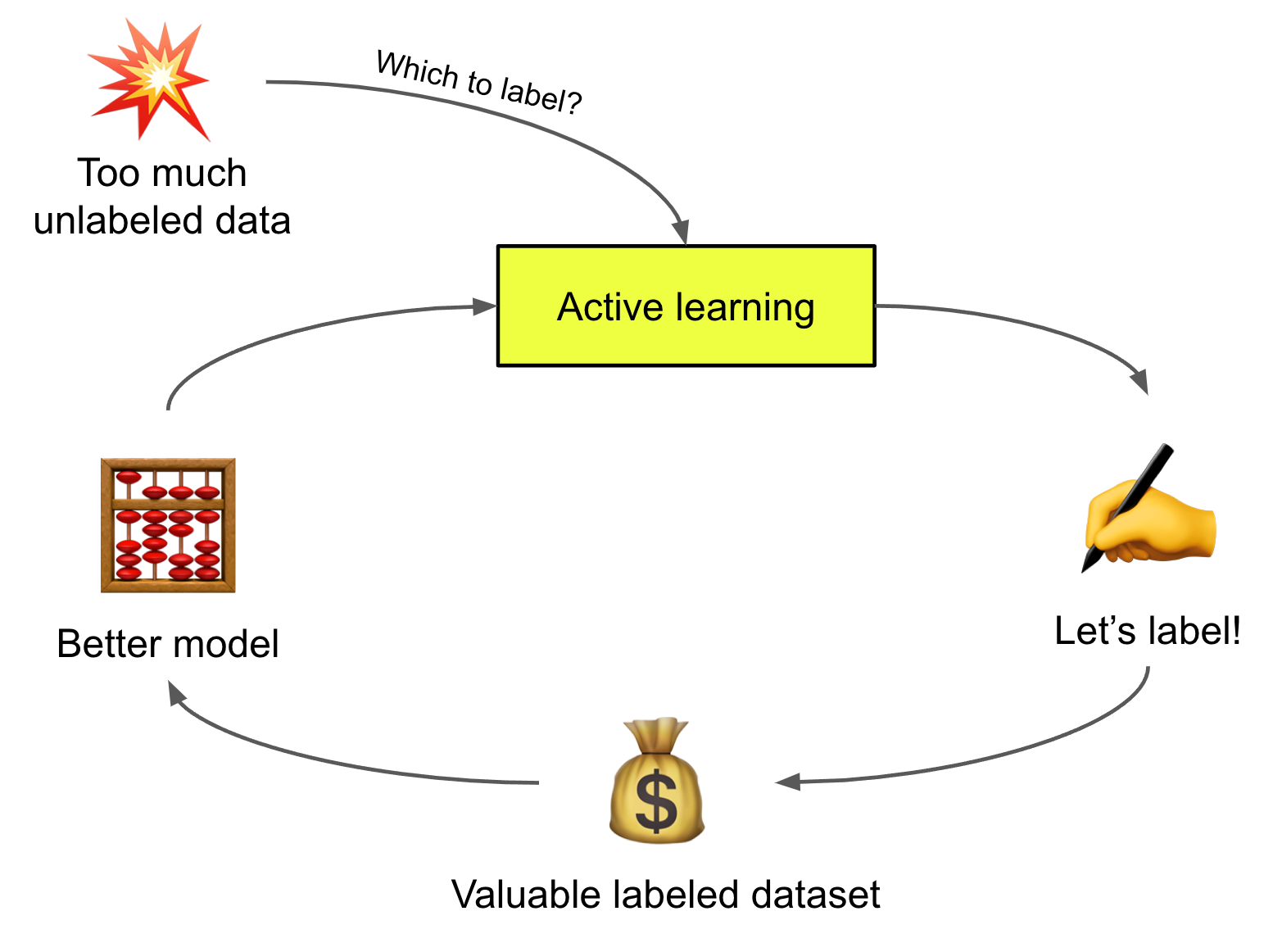
4. Mục tiêu của Active Learning
-
Tối ưu hóa hiệu quả của quá trình học máy: Active learning tận dụng tối đa lợi ích của dữ liệu để cải thiện hiệu suất của mô hình học máy.
-
Tiết kiệm thời gian và chi phí cho việc thu thập dữ liệu: Active learning chọn những mẫu dữ liệu có giá trị nhất để được gán nhãn và sử dụng cho huấn luyện, giúp tiết kiệm thời gian và chi phí cho việc thu thập dữ liệu.
-
Cải thiện độ chính xác và độ tin cậy của mô hình: Những mẫu dữ liệu được chọn bởi active learning có khả năng cải thiện độ chính xác và độ tin cậy của mô hình học máy.
-
Điều chỉnh mô hình học máy một cách linh hoạt: Active learning giúp điều chỉnh mô hình học máy một cách linh hoạt và nhanh chóng khi có thêm dữ liệu mới được gán nhãn.
-
Xử lý các vấn đề về dữ liệu không đồng nhất: Active learning giúp xử lý các vấn đề về dữ liệu không đồng nhất bằng cách chọn những mẫu dữ liệu mang tính đại diện để đảm bảo tính đa dạng của dữ liệu từ đó giúp mô hình đạt được sự tổng quát hóa.
5. Khi nào sử dụng Active Learning
-
Dữ liệu là tài nguyên quý giá: Khi dữ liệu là tài nguyên quý giá và việc thu thập dữ liệu mới gian khổ hoặc đắt đỏ, Active Learning có thể giúp tận dụng tối đa dữ liệu hiện có để đạt được hiệu quả cao trong quá trình huấn luyện mô hình học máy .
-
Quá trình gán nhãn dữ liệu là tốn kém: Khi quá trình gán nhãn dữ liệu là tốn kém và tốn thời gian, Active Learning có thể giúp tiết kiệm thời gian và chi phí bằng cách chỉ chọn những mẫu dữ liệu quan trọng nhất để gán nhãn mà các chiến lược random sampling không phát huy tác dụng.
-
Có sự khác biệt lớn về chất lượng dữ liệu: Khi có sự khác biệt lớn về chất lượng dữ liệu, Active Learning có thể giúp xử lý vấn đề này bằng cách chọn những mẫu dữ liệu có chất lượng cao để đảm bảo tính đáng tin cậy của mô hình học máy.
-
Cần đạt được kết quả cao với số lượng dữ liệu nhỏ: Khi cần đạt được kết quả cao với số lượng dữ liệu nhỏ, Active Learning có thể giúp tăng hiệu suất của mô hình học máy bằng cách tận dụng tối đa dữ liệu.
-
Mô hình học máy cần được cập nhật liên tục: Khi mô hình học máy cần được cập nhật liên tục với dữ liệu mới, Active Learning có thể giúp đảm bảo tính linh hoạt và nhanh chóng của quá trình huấn luyện mô hình học máy.
6. Các hướng tiếp cận trong Active Learning
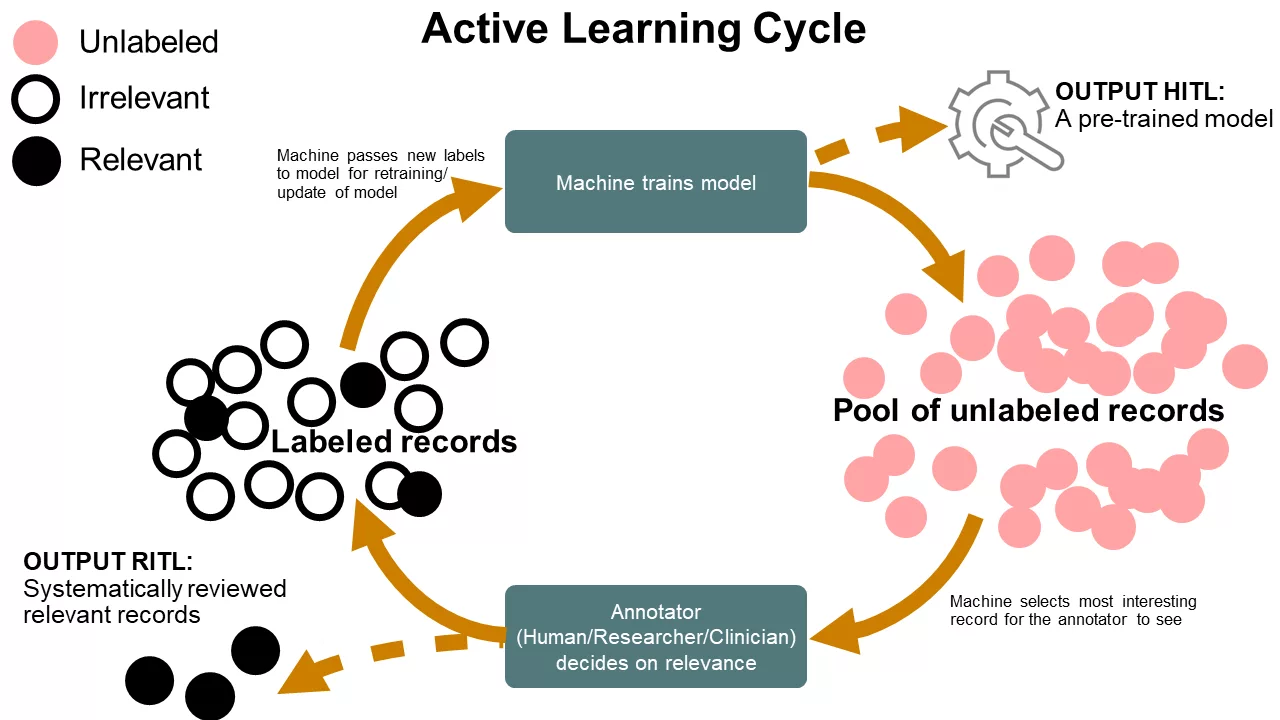
Các bước trong active learning pipeline bao gồm:
-
Xác định dữ liệu đầu vào: Lựa chọn dữ liệu ban đầu từ tập dữ liệu toàn bộ để huấn luyện mô hình học máy.
-
Huấn luyện mô hình: Sử dụng dữ liệu đầu vào để huấn luyện mô hình học máy ban đầu.
-
Chọn các mẫu không được gán nhãn: Sử dụng mô hình học máy ban đầu để đánh giá các mẫu chưa được gán nhãn và chọn ra những mẫu quan trọng nhất cho quá trình tiếp theo.
-
Gán nhãn các mẫu quan trọng: Những mẫu được chọn sẽ được gán nhãn bởi một chuyên gia hoặc một thuật toán.
-
Mở rộng tập dữ liệu: Các mẫu đã được gán nhãn được thêm vào tập dữ liệu huấn luyện để tăng độ phủ của tập dữ liệu.
-
Huấn luyện lại mô hình: Sử dụng tập dữ liệu mở rộng để huấn luyện lại mô hình học máy và đánh giá hiệu suất của nó.
Quá trình từ bước 3 đến bước 6 được lặp lại cho đến khi đạt được độ chính xác mong muốn hoặc không còn cách nào để giảm số lượng dữ liệu được gán nhãn. Quá trình này được gọi là iterative process trong Active Learning.
Ba hướng Data Sampling chính:
-
Random sampling: là phương pháp lấy mẫu ngẫu nhiên từ tập dữ liệu để được gán nhãn. Phương pháp này đơn giản và dễ thực hiện, tuy nhiên nó không đảm bảo sự hiệu quả của quá trình huấn luyện mô hình.
-
Uncertainty sampling: là phương pháp lấy những mẫu mà mô hình không chắc chắn về kết quả dự đoán để được gán nhãn. Phương pháp này được xây dựng dựa trên giả định rằng những mẫu mà mô hình không chắc chắn về kết quả dự đoán sẽ cần được gán nhãn để cải thiện hiệu suất của mô hình. Các phương pháp uncertainty sampling phổ biến bao gồm:
- Margin sampling: Lựa chọn các mẫu mà khoảng cách giữa các xác suất được dự đoán của hai lớp gần bằng nhau.
- Entropy sampling: Lựa chọn các mẫu mà entropy của xác suất dự đoán của các lớp lớn hơn.
- Diversity sampling: là phương pháp lấy những mẫu mà đại diện cho các khía cạnh đa dạng của tập dữ liệu để được gán nhãn. Phương pháp này được xây dựng dựa trên giả định rằng các mẫu đại diện cho các khía cạnh đa dạng của tập dữ liệu sẽ cần được gán nhãn để giúp mô hình học được các mẫu khác trong tập dữ liệu. Các phương pháp diversity sampling phổ biến bao gồm:
- Cluster sampling: Lựa chọn các mẫu trong các cụm khác nhau của tập dữ liệu để đảm bảo đại diện cho các cụm dữ liệu khác nhau.
- Representative sampling: Lựa chọn các mẫu mà đại diện cho các đặc trưng quan trọng của tập dữ liệu để đảm bảo đại diện cho các đặc trưng quan trọng của tập dữ liệu.
Ở phần này, ta đã cùng nhau tìm hiểu
- Tầm quan trọng của dữ liệu trong AI/ML
- Các khái niệm cơ bản về Active Learning
- Các hướng tiếp cận chính của Active Learning Ở phần sau, ta sẽ đi sâu tìm hiể về:
- Lý thuyết và thực hành Uncertainty Sampling vào bài toán cụ thể. Các bạn cùng đón xem nhé !
7. Tham khảo
[1]. https://viblo.asia/p/lam-gi-khi-mo-hinh-hoc-may-thieu-du-lieu-co-nhan-phan-1-tong-quan-ve-active-learning-RQqKLRLbl7z
[2]. https://viblo.asia/p/khoa-hoc-active-learning-bai-1-tong-quan-ve-active-learning-GyZJZNZ8Jjm
