

Post 10 - Hacking trong Deep Learning

1. Hacking trong Deep Learning
Chắc hẳn bản thân mình và người đọc là các bạn đã từng nghe nhiều tới khái niệm “Hacking” trong giới lập trình viên, nhưng ta thường nhầm lẫn rằng việc các hackers cố gắng xuyên thủng phần mềm nhằm đánh cắp dữ liệu, tàn phá hệ thống,.. chỉ tồn tại trong các hệ thống mạng hay dịch vụ mà không tồn tại trong các hệ thống học máy, deeplearing nói riêng. Nhưng thực tế là bất kỳ, hệ thống phần mềm nào đều có lỗ hổng và các hackers có thể lợi dùng đó gây ra thiệt hại lớn tùy thuộc vào quy mô hệ thống và mức độ nghiệm trọng của lỗ hổng, đặc biệt là trong hệ thống Deep Learning.
Giả sử một hệ thống an ninh dùng nhận diện khuôn mặt để kiểm soát ra vào. Sẽ ra sao nếu mình chỉ cần tí chỉnh sửa là có thể qua mặt hệ thống AI chứ? Nếu đó là các cơ quan quan trọng thì hậu quả để lại sẽ không biết nghiệm trong tới mức nào? Đây chỉ là một ví dụ đơn giản, còn rất nhiều ứng dụng AI trong cuộc sống và mỗi ứng dụng đều có những lỗ hổng có thể bị lợi dụng. Thậm chí mạng nơron tân tiến nhất cũng có thể dễ dàng bị đánh lừa. Chỉ cần với một vài thủ thuật, bạn có thể khiến chúng dự đoán bất kể kết quả nào mà bạn muốn. Có khái niệm tấn công (hacking) thì sẽ có phòng thủ, vậy qua bài viết này mình sẽ cung cấp cho các bạn tổng quan về vấn đề tấn công và phòng thủ trong Deep Learning.
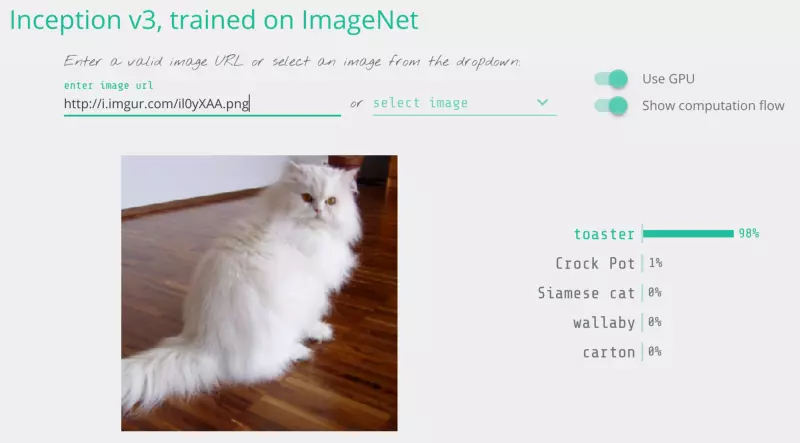
2. Tấn công (hacking) trong Deep Learning
Do mô hình học sâu có không gian đầu vào rất lớn và độ phức tạp lớn, nếu nó nhớ các dữ liệu đầu vào và khiến đường phân lớp (decision boundary) cố fit các điểm nhiễu, chúng ta có thể dễ dàng sửa đầu vào cho giống điểm data nhiễu kia để lừa mô hình. Đó là lý do tại sao các phương pháp data augmentation như thêm nhiễu/trộn đầu vào giúp cho mô hình không bị overfit vào training set. Chưa kể, đa số các mô hình hiện đại đều sử dụng batchnorm để có thể thành công train các model sâu, nhưng batchnorm lại khiến model dễ bị tấn công hơn rất nhiều.
Dưới đây là hình ảnh đồ họa một phân chia 2 nhóm đơn giản
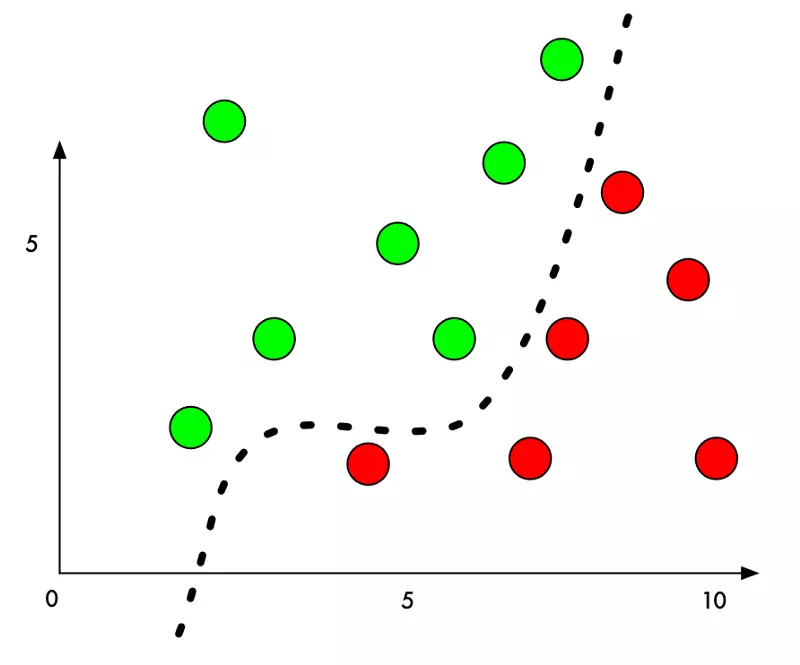
Ngay bây giờ, thuật toán phân nhóm chính xác 100%. Nó đã tìm ra đường chính xác để phân chia 2 nhóm.
Nhưng nếu chúng ta muốn ngụy trang một điểm đỏ là điểm xanh thì sao? Chúng ta chỉ cần thêm một lượng nhỏ vào giá trị Y của điểm đỏ, bên cạnh đường biên, để đẩy điểm này vào lãnh thổ điểm xanh.
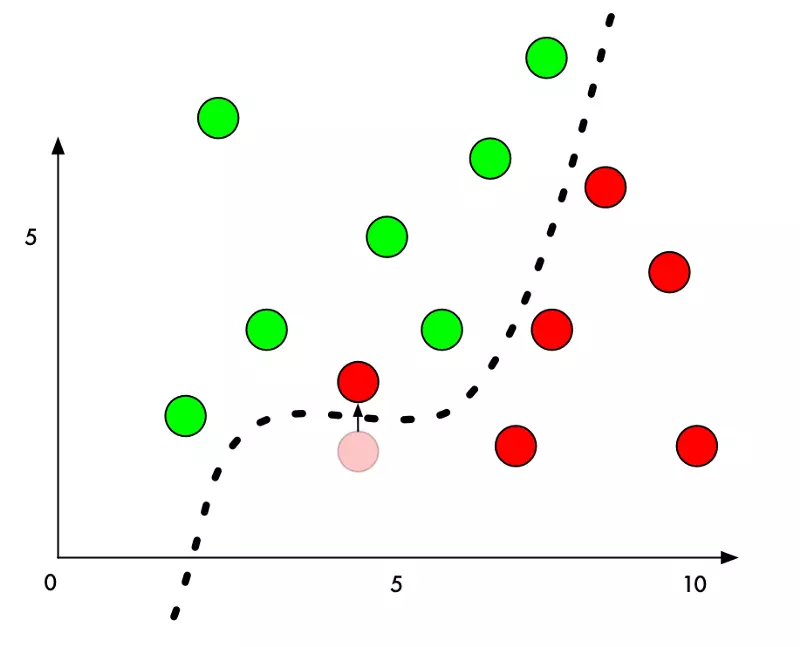
Vì thế, để đánh lừa thuật toán phân chia, ta chỉ cần biết hướng thay đổi của từng pixel để khiến ảnh vượt qua đường phân chia. Và bởi vì chúng ta không muốn ai phát hiện ra sự thay đổi có chủ đích này, ta cố gắng thay đổi ít nhất có thể.
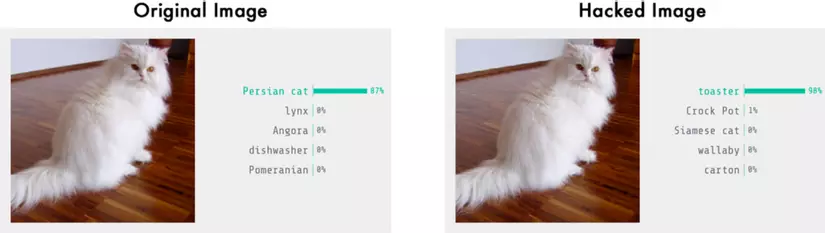
Hay nói cách khác, chỉ cần một ảnh thật, ta thay đổi rất ít giá trị pixels để đánh lừa mạng nơron. Và ta đã có thể hoàn toàn kiểm soát giá trị đầu ra của mạng.
2.1. Yêu cầu tấn công
Chúng ta sẽ xem lại quá trình đạo tạo mạng neural để phân loại ảnh:
- Truyền tập ảnh đào tạo vào.
- Kiểm tra dự đoán mạng nơron và xem độ lệch với kết quả chính xác
- Tinh chỉnh trọng số mỗi lớp mạng sử dụng back-propagation (truyền ngược) để có kết quả dự đoán cuối cùng tốt hơn.
- Lặp lại bước 1-3 vài nghìn lần cùng với hàng ngàn ảnh đào tạo
Nhưng nếu thay vì thay đổi trọng số của mỗi lớp nơron ở bước 3, ta tinh chỉnh ảnh đầu vào cho tới khi chúng ta có được kết quả chúng ta muốn thì sao?
Hãy cùng lấy mạng nơron đã được đào tạo và “đào tạo” nó thêm một lần nữa. Nhưng lần này, ta sử dụng back-propagation để thay đổi ảnh đầu vào thay vì trọng số từng nơron.

Đây là thuật toán mới:
- Truyền vào ảnh chúng ta muốn hack
- Kiểm tra dự đoán mạng và xem độ lệch với kết quả ta muốn nhận
- Tinh chỉnh ảnh sử dụng back-propagation để có dự đoán cuối cùng gần với kết quả ta mong muốn
- Lặp lại bước 1-3 hàng ngàn lần với cùng tấm ảnh đó cho tới khi mạng cho ta kết quả mong chờ.
- Và giờ, ta đã có một bức ảnh đánh lừa được mạng nơron mà không thay đổi bất cứ giá trị nào của mạng.
Để hạn chế biến dạng ảnh rõ ràng, chúng ta thêm điều kiện cho thuật toán: mỗi giá trị pixel không được thay đổi nhiều hơn một giá trị rất nhỏ từ ảnh cũ - ví dụ 0.01%. Điều đó buộc thuật toán phải thay đổi tấm ảnh để vừa đánh lừa được mạng nơron, vừa không thay đổi quá khác biệt và đánh lừa được mắt thường.
Độ khác nhau thường được tính bằng norm. Độ khác nhau đó sẽ bị giới hạn trên sao cho ảnh mới nhìn trông vẫn giống ảnh gốc. Ví dụ, trong trường hợp sử dụng , và độ chênh lệch tối đa là $l_2$ hoặc $l_{\infty}$, chúng ta có yêu cầu như sau: $||x - x’||_{infty} \le $
