

Post 4 - Object Detection Overview
Các ứng dụng của giác máy tính là làm cho máy tính hiểu được hình ảnh kỹ thuật số cũng như dữ liệu trực quan từ thế giới thực. Điều này có thể liên quan đến việc trích xuất, xử lý và phân tích thông tin từ các đầu vào đó để đưa ra quyết định.
Sự phát triển của thị giác máy đã phân loại hóa các bài toán khó thành các phát biểu bài toán phổ biến có thể giải được. Việc phân chia các chủ đề thành các nhóm bài toán phù hợp đã giúp các nhà nghiên cứu trên toàn cầu xác định các vấn đề và giải quyết chúng một cách hiệu quả.
Các tác vụ thị giác máy tính phổ biến nhất mà chúng ta thường thấy trong thuật ngữ AI bao gồm:
- Phân loại hình ảnh (image classification): liên quan đến việc gán nhãn cho hình ảnh.
- Định vị vật thể (object localization): Xác định một hộp giới hạn (bounding box) xung quanh một hoặc nhiều đối tượng trong hình ảnh nhằm khoanh vùng đối tượng.
- Phát hiện đối tượng (object detection): Là nhiệm vụ khó khăn hơn và là sự kết hợp của cả hai nhiệm vụ trên: Vẽ một bounding box xung quanh từng đối tượng quan tâm trong ảnh và gán cho chúng một nhãn. Kết hợp cùng nhau, tất cả các vấn đề này được gọi là object recognition hoặc object detection. Bài viết này sẽ giới thiệu một cách khái quát các vấn đề của object detection và các mô hình deep learning state-of-art được thiết kế để giải quyết nó.
1. Object Detection là gì?
Nhận dạng đối tượng là một thuật ngữ chung để mô tả một tập hợp các nhiệm vụ thị giác máy tính có liên quan liên quan đến việc xác định các đối tượng trong ảnh kỹ thuật số.
Phân loại hình ảnh liên quan đến việc dự đoán lớp của một đối tượng trong một hình ảnh. Định vị vật thể đề cập đến việc xác định vị trí của một hoặc nhiều đối tượng trong một hình ảnh và vẽ bounding box xung quanh chúng. Phát hiện đối tượng kết hợp hai nhiệm vụ trên và thực hiện cho một hoặc nhiều đối tượng trong hình ảnh. Chúng ta có thể phân biệt giữa ba nhiệm vụ thị giác máy tính cơ bản trên thông qua input và output của chúng như sau:
- Image classification: Dự đoán nhãn của một đối tượng trong một hình ảnh.
- Input: Một hình ảnh với một đối tượng, chẳng hạn như một bức ảnh.
- Output: Dán nhãn (label) cho hình ảnh (ví dụ: một hoặc nhiều số nguyên được ánh xạ tới label).
- Object location: Xác định vị trí hiện diện của các đối tượng trong ảnh và cho biết vị trí của chúng bằng bounding box.
- Input: Một hình ảnh có một hoặc nhiều đối tượng.
- Output: Một hoặc nhiều bounding box được xác định bởi tọa độ tâm, chiều rộng và chiều cao.
- Object detection: Xác định vị trí hiện diện của các đối tượng trong bounding box và nhãn của các đối tượng nằm trong một hình ảnh.
- Input: Một hình ảnh có một hoặc nhiều đối tượng, chẳng hạn như một bức ảnh.
- Output: Một hoặc nhiều bounding box và nhãn cho mỗi bounding box.
Một số định nghĩa khác cũng rất quan trọng trong computer vision là phân đoạn đối tượng (object segmentation), trong đó các đối tượng được nhận dạng bằng cách làm nổi bật các pixel cụ thể của đối tượng thay vì bounding box. Và image captioning kết hợp giữa các kiến trúc mạng CNN và LSTM để đưa ra các lý giải về hành động hoặc nội dung của một bức ảnh.
Hình dưới mô tả các nhiệm vụ thị giác máy tính cơ bản, trong đó object segmentation được chia thành 2 loại là:
- Semantic segmentation: phân đoạn đối tượng theo lớp, chẳng hạn như phân đoạn đối tượng thành các lớp như: người, xe, cây, núi, v.v.
- Instance segmentation: phân đoạn đối tượng theo thể hiện, chẳng hạn như phân đoạn đối tượng thành các thể hiện như: người 1, người 2, xe 1, xe 2, v.v.

Điểm khác biệt nữa trong các mô hình image classification so với Object Recognition đó là mô hình image classification có hàm loss function chỉ dựa trên sai số giữa nhãn dự báo và nhãn thực tế trong khi object detection đánh giá dựa trên sai số giữa nhãn dự báo và sai số khung hình dự báo so với thực tế.
2. Thuật ngữ
- region proposal: Vùng đề xuất, là những vùng mà có khả năng chứa đối tượng hoặc hình ảnh ở bên trong nó.
- bounding box: Là hình chữ nhật được vẽ bao quan đối tượng nhằm xác định đối tượng.
- offsets: Là các tham số giúp xác định bounding box bao gồm tâm của bounding box (x, y) và chiều dài, chiều rộng (w, h).
- anchor box: Chính là một bounding box cơ sở để xác định bounding box bao quanh vật thể dựa trên các phép dịch tâm và scale kích thước chiều dài, rộng. Mỗi loại anchor box sẽ phù hợp để tìm ra bounding box cho 1 loại vật thể đặc trưng. Chẳng hạn vật thể là con người thường có chiều cao > chiều rộng trong khi đoàn tàu sẽ có chiều rộng lớn hơn nhiều lần chiều cao.
- feature: Các đặc trưng được tạo ra từ một mạng deep CNN chẳng hạn Alexnet hoặc VGG16 giúp nhận diện nhãn của hình ảnh.
- pipeline: Là một tợp hợp các bước xử lý liên tiếp nhận đầu vào là dữ liệu (ảnh, âm thanh, các trường dữ liệu) và trả ra kết quả dự báo ở output.
3. Mô hình R-CNN
R-CNN (regions with CNN features hay Region-Based Convolutional Neural Network) là lớp các mô hình xác định vùng đặc trưng dựa trên các mạng CNN được phát triển bởi Ross Girshick và các cộng sự. Lớp các mô hình này gồm 3 mô hình chính là R-CNN, Fast R-CNN và Faster-RCNN được thiết kế cho các nhiệm vụ định vị vật thể và nhận diện vật thể.
Chúng ta sẽ đi vào tìm hiểu các mô hình này.
3.1 R-CNN (2014)
R-CNN được giới thiệu lần đầu vào 2014 bởi Ross Girshick và các cộng sự ở UC Berkeley một trong những trung tâm nghiên cứu AI hàng đầu thế giới trong bài báo Rich feature hierarchies for accurate object detection and semantic segmentation.
Nó có thể là một trong những ứng dụng nền móng đầu tiên của mạng nơ ron tích chập đối với vấn đề định vị, phát hiện và phân đoạn đối tượng. Cách tiếp cận đã được chứng minh trên các bộ dữ liệu điểm chuẩn, đạt được kết quả tốt nhất trên bộ dữ liệu VOC-2012 và bộ dữ liệu phát hiện đối tượng ILSVRC-2013 gồm 200 lớp.
Kiến trúc của R-CNN gồm 3 thành phần đó là:
-
Vùng đề xuất hình ảnh (Region proposal): Có tác dụng tạo và trích xuất các vùng đề xuất chứa vật thể được bao bởi các bounding box.
-
Trích lọc đặc trưng (Feature Extractor): Trích xuất các đặc trưng giúp nhận diện hình ảnh từ các region proposal thông qua các mạng deep convolutional neural network.
-
Phân loại (classifier): Dựa vào input là các features ở phần trước để phân loại hình ảnh chứa trong region proposal về đúng nhãn. Ví dụ: linear SVM classifier model.
Kiến trúc của mô hình được mô tả trong biểu đồ bên dưới:
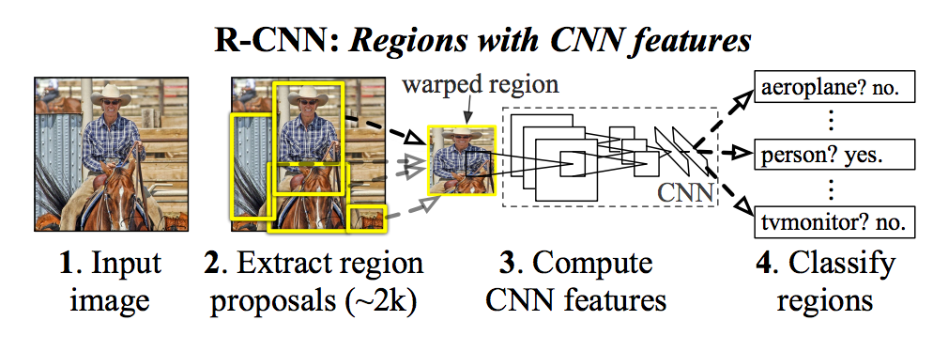
Một kỹ thuật được sử dụng để đề xuất các region proposal hoặc các bounding box chứa các đối tượng tiềm năng trong hình ảnh được gọi là “selective search”, các region proposal có thể được phát hiện bởi đa dạng những thuật toán khác nhau. Nhưng điểm chung là đều dựa trên tỷ lệ IoU giữa bounding box và ground truth box mà bạn đọc sẽ được tìm hiểu ở bài viết tiếp theo giới thiệu về mạng SSD.
Trích xuất đặc trưng về bản chất là một mạng CNN học sâu, ở đây là AlexNet, mạng đã giành chiến thắng trong cuộc thi phân loại hình ảnh ILSVRC-2012. Đầu ra của CNN là một vectơ 4096 chiều mô tả nội dung của hình ảnh được đưa đến một mô hình SVM tuyến tính để phân loại.
Đây là một ứng dụng tương đối đơn giản và dễ hiểu của CNN đối với vấn đề object localization và object detection. Một nhược điểm của phương pháp này là chậm, đòi hỏi phải vượt qua nhiều module độc lập trong đó có trích xuất đặc trưng từ một mạng CNN học sâu trên từng region proposal được tạo bởi thuật toán đề xuất vùng chứa ảnh. Đây là một vấn đề chính cần giải quyết vì bài viết mô tả mô hình hoạt động trên khoảng 2000 vùng được đề xuất cho mỗi hình ảnh tại thời điểm thử nghiệm.
Mã nguồn Python (Caffe) và MatLab cho R-CNN như được mô tả trong bài viết đã được cung cấp trong kho GitHub repository của R-CNN.
3.2 Fast R-CNN (2015)
Dựa trên thành công của R-CNN, Ross Girshick (lúc này đã chuyển sang Microsoft Research) đề xuất một mở rộng để giải quyết vấn đề của R-CNN trong một bài báo vào năm 2015 với tiêu đề rất ngắn gọn Fast R-CNN.
Bài báo chỉ ra những hạn chế của R-CNN đó là:
- Training qua một pipeline gồm nhiều bước: Pipeline liên quan đến việc chuẩn bị và vận hành ba mô hình riêng biệt.
- Chi phí training tốn kém về số lượng bounding box và thời gian huấn luyện: Mô hình huấn luyện một mạng CNN học sâu trên rất nhiều region proposal cho mỗi hình ảnh nên rất chậm.
- Phát hiện đối tượng chậm: Tốc độ xử lý không thể đảm bảo realtime.
- Trước đó một bài báo đã đề xuất phương pháp để tăng tốc kỹ thuật được gọi là mạng tổng hợp kim tự tháp - Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, hoặc SPPnets vào năm 2014. Phương pháp này đã tăng tốc độ trích xuất features nhờ lan truyền thuận trên bộ nhớ đệm.
Điểm đột phá của Fast R-CNN là sử dụng một single model thay vì pipeline để phát hiện region và classification cùng lúc.
Kiến trúc của mô hình trích xuất từ bức ảnh một tập hợp các region proposals làm đầu vào được truyền qua mạng deep CNN. Một pretrained-CNN, chẳng hạn VGG-16, được sử dụng để trích lọc features. Phần cuối của deep-CNN là một custom layer được gọi là layer vùng quan tâm (Region of Interest Pooling - RoI Pooling) có tác dụng trích xuất các features cho một vùng ảnh input nhất định.
Sau đó các features được kết bởi một lớp fully connected. Cuối cùng mô hình chia thành hai đầu ra, một đầu ra cho dự đoán nhãn thông qua một softmax layer và một đầu ra khác dự đoán bounding box (kí hiệu là bbox) dựa trên hồi qui tuyến tính. Quá trình này sau đó được lặp lại nhiều lần cho mỗi vùng RoI trong một hình ảnh.
Kiến trúc của mô hình được tóm tắt trong hình dưới đây, được lấy từ bài báo.
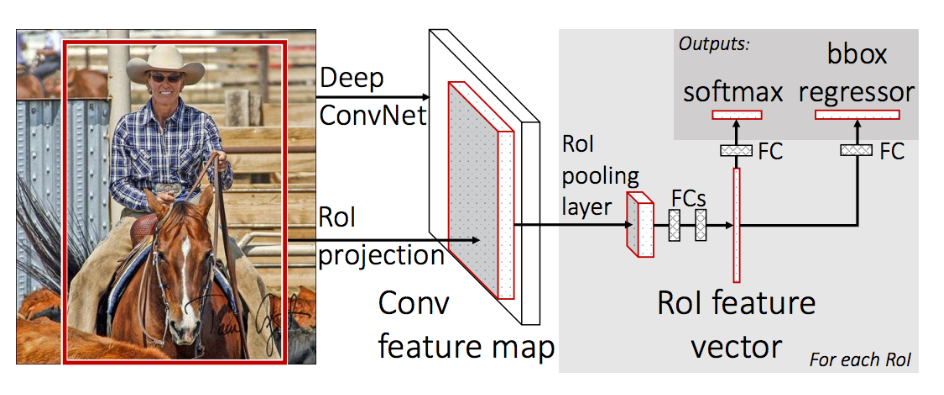
Mô hình này nhanh hơn đáng kể cả về huấn luyện và dự đoán, tuy nhiên vẫn cần một tập hợp các region proposal được đề xuất cùng với mỗi hình ảnh đầu vào.
Mã nguồn Python và C ++ (Caffe) cho Fast R-CNN như được mô tả trong bài báo xem tại Fast - RCNN.
3.3 Faster R-CNN (2016)
Kiến trúc mô hình đã được cải thiện hơn nữa về cả tốc độ huấn luyện và phát hiện được đề xuất bởi Shaoqing Ren và các cộng sự tại Microsoft Research trong bài báo năm 2016 có tiêu đề Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Dịch nghĩa là “Faster R-CNN: Hướng tới phát hiện đối tượng theo thời gian thực với các mạng đề xuất khu vực”.
Kiến trúc này mang lại độ chính xác cao nhất đạt được trên cả hai nhiệm vụ phát hiện và nhận dạng đối tượng tại các cuộc thi ILSVRC-2015 và MS COCO-2015.
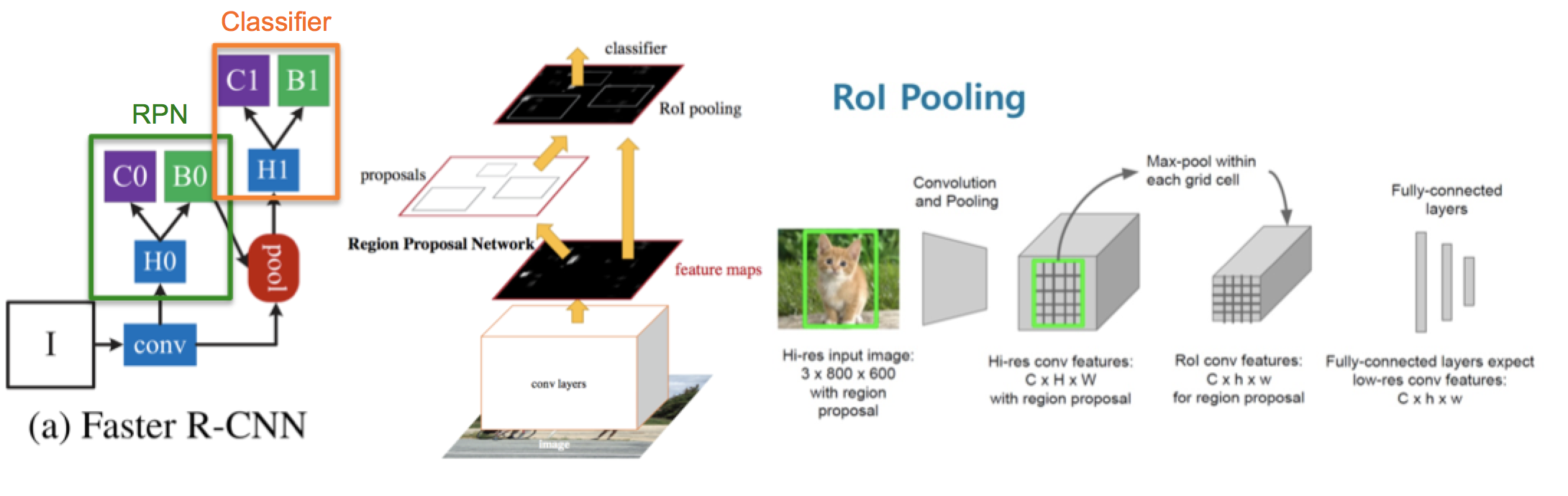
Kiến trúc được thiết kế để đề xuất và tinh chỉnh các region proposals như là một phần của quá trình huấn luyện, được gọi là mạng đề xuất khu vực (Region Proposal Network), hoặc RPN. Các vùng này sau đó được sử dụng cùng với mô hình Fast R-CNN trong một thiết kế mô hình duy nhất. Những cải tiến này vừa làm giảm số lượng region proposal vừa tăng tốc hoạt động trong thời gian thử nghiệm mô hình lên gần thời gian thực với hiệu suất tốt nhất. Tốc độ là 5fps trên một GPU.
Mặc dù là một mô hình đơn lẻ duy nhất, kiến trúc này là kết hợp của hai modules:
- Mạng đề xuất khu vực (Region Proposal Network, viết tắT là RPN). Mạng CNN để đề xuất các vùng và loại đối tượng cần xem xét trong vùng.
- Fast R-CNN: Mạng CNN để trích xuất các features từ các region proposal và trả ra các bounding box và nhãn. Cả hai modules hoạt động trên cùng một output của một mạng deep CNN. Mạng RPN hoạt động như một cơ chế attention cho mạng Fast R-CNN, thông báo cho mạng thứ hai về nơi cần xem hoặc chú ý.
Kiến trúc của mô hình được tổng kết thông qua sơ đồ bên dưới:
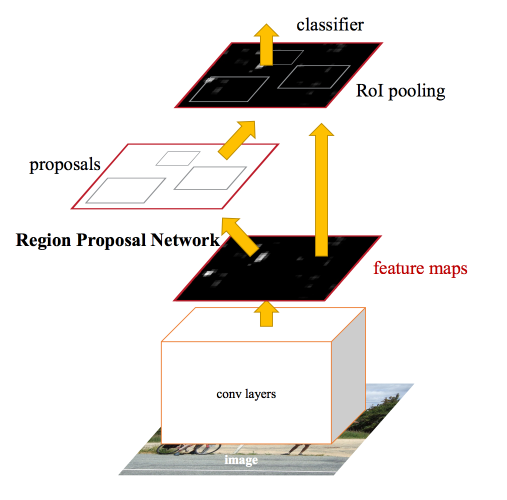
RPN hoạt động bằng cách lấy đầu ra của một mạng pretrained deep CNN, chẳng hạn như VGG-16, và truyền feature map vào một mạng nhỏ và đưa ra nhiều region proposals và nhãn dự đoán cho chúng. Region proposals là các bounding boxes, dựa trên các anchor boxes hoặc hình dạng được xác định trước được thiết kế để tăng tốc và cải thiện khả năng đề xuất vùng. Dự đoán của nhãn được thể hiện dưới dạng nhị phân cho biết region proposal có xuất hiện vật thể hoặc không.
Một quy trình huấn luyện xen kẽ được sử dụng trong đó cả hai mạng con được đào tạo cùng một lúc. Điều này cho phép các tham số trong feature dectector của deep CNN được tinh chỉnh cho cả hai tác vụ cùng một lúc.
Tại thời điểm viết, kiến trúc Faster R-CNN này là đỉnh cao của họ model R-CNN và tiếp tục đạt được kết quả gần như tốt nhất trong các nhiệm vụ nhận diện đối tượng. Một mô hình mở rộng hỗ trợ cho phân đoạn hình ảnh, được mô tả trong bài báo năm 2017 có tựa đề Mask R-CNN.
Mã nguồn Python và C ++ (Caffe) cho Fast R-CNN như được mô tả trong bài báo có thể tham khảo tại Faster R-CNN.
3.4 Mask R-CNN (2017)
Mask RCNN là một state-of-the-art cho bài toán về segmentation và object detection. Mask R-CNN về cơ bản là phần mở rộng của Faster R-CNN. Faster R-CNN được sử dụng rất nhiều trong các bài toán phát hiện đối tượng. Trong paper gốc của tác giả có nói và mình xin trích xuất đầy đủ như sau : “The Mask R-CNN framework is built on top of Faster R-CNN”. Khác với Faster R-CNN ở chỗ khi bạn cho một hình ảnh vào ngoài việc trả ra label và bouding box của từng object trong một hình ảnh thì nó sẽ thêm cho chúng ta các object mask.
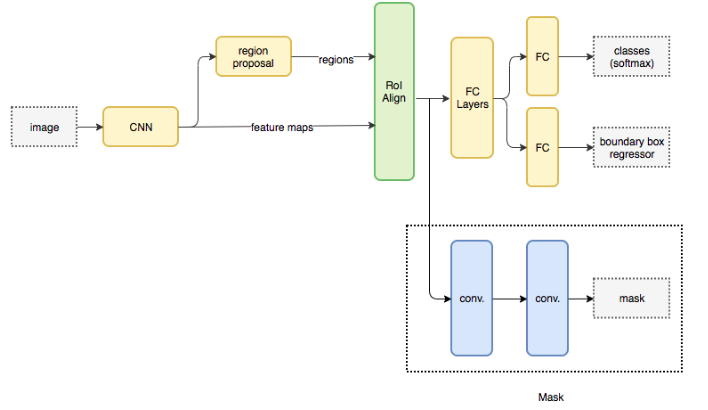
Chúng ta có ROI dựa trên những giá trị IOU (IoU = Area of the intersection / Area of the union) qua việc tính toán nên tác giả đã thêm một nhánh mask vào trong kiến trúc hiện tại.
3.5 Cascade R-CNN (2017)
Cascade R-CNN là một biến thể của dòng mô hình phát hiện đối tượng R-CNN được giới thiệu vào năm 2018. Nó được xây dựng dựa trên mô hình R-CNN ban đầu và thêm một loạt trình phân loại để tinh chỉnh kết quả phát hiện đối tượng, giúp cải thiện sự chính xác.
Mô hình Cascade R-CNN hoạt động bằng cách đào tạo một chuỗi các bộ phân loại (classifier), trong đó mỗi bộ phân loại được đào tạo dựa trên đầu ra của bộ phân loại trước đó với ngưỡng tin cậy cao hơn (confidence threshold). Trình phân loại đầu tiên được đào tạo trên tập đề xuất đối tượng ban đầu do mạng đề xuất khu vực (RPN) tạo ra, trong khi các trình phân loại tiếp theo được đào tạo dựa trên đầu ra của trình phân loại trước đó với ngưỡng tin cậy cao hơn. Tầng phân loại này cho phép Cascade R-CNN lọc ra các kết quả dương tính giả hiệu quả hơn và cải thiện độ chính xác của việc phát hiện.
Cascade R-CNN đã đạt được hiệu suất cao nhất trên điểm chuẩn COCO và đã được sử dụng rộng rãi trong nhiều ứng dụng khác nhau như lái xe tự động, giám sát video và chế tạo rô-bốt. Tuy nhiên, một nhược điểm của Cascade R-CNN là nó có thể tốn kém về mặt tính toán do có nhiều giai đoạn xử lý liên quan, điều này có thể hạn chế việc sử dụng nó trong các ứng dụng thời gian thực hoặc ứng dụng có tài nguyên tính toán hạn chế.
Bất chấp những hạn chế của nó, Cascade R-CNN vẫn là một mô hình được đánh giá cao và được sử dụng rộng rãi trong cộng đồng phát hiện đối tượng và đã truyền cảm hứng cho sự phát triển của các mô hình dựa trên tầng khác, chẳng hạn như Cascade Mask R-CNN, mở rộng ý tưởng về Cascade R-CNN đến nhiệm vụ phân đoạn cá thể (instance segmentation).
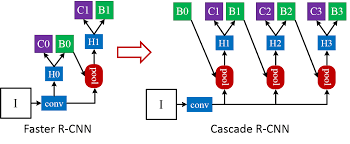
Ngoài ra còn có các biến thể và phần mở rộng khác của R-CNN, chẳng hạn như R-FCN (Region-based Fully Convolutional Networks), sử dụng position-sensitive RoI pooling và Light R-CNN, sử dụng các mô hình nhẹ cho thời gian thực phát hiện đối tượng trên thiết bị di động nhưng vì phạm vi bài viết nên chúng ta sẽ không đi sâu vào các mô hình này.
4. SSD (Single Shot MultiBox Detector) (2016)
Đặc điểm của các model trước là tốc độ xử lý thấp, không đáp ứng được trong việc object dection realtime. Các mạng start-of-art hơn như SSD và YOLO là những kiến trúc có tốc độ xử lý nhanh mà vẫn đảm bảo về độ chính xác nhờ những thay đổi trong kiến trúc mạng nhằm gói gọn quá trình phát hiện và phân loại vật thể trong 1 lần và cắt bớt được các xử lý không cần thiết.
Single Shot MultiBox Detector (SSD) là một thuật toán thị giác máy tính phổ biến được sử dụng để phát hiện đối tượng trong hình ảnh và video. Nó được giới thiệu lần đầu tiên bởi Wei Liu, Dragomir Anguelov và các nhà nghiên cứu khác tại Google vào năm 2016.
Mục tiêu của phát hiện đối tượng là xác định và định vị các đối tượng quan tâm trong một hình ảnh hoặc video. SSD là một loại kiến trúc mạng thần kinh có thể đạt được độ chính xác cao trong phát hiện đối tượng theo thời gian thực bằng cách dự đoán sự hiện diện và vị trí của các đối tượng trong hình ảnh chỉ trong một lần.
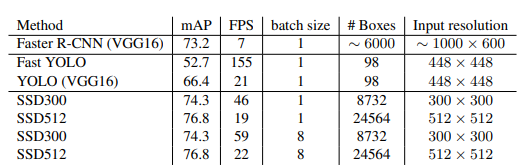
Cũng giống như hầu hết các kiến trúc object detection khác, đầu vào của SSD là tọa độ bounding box của vật thể (hay còn gọi là offsets của bounding box) và nhãn của vật thể chứa trong bounding box. Điểm đặc biệt làm nên tốc độ của SSD model là mô hình sử dụng một mạng neural duy nhất. Cách tiếp cận của nó dựa trên việc nhận diện vật thể trong các features map (là một output shape 3D của một mạng deep CNN sau khi bỏ các fully connected layers cuối) có độ phân giải khác nhau. Mô hình sẽ tạo ra một lưới các ô vuông gọi là grid cells trên các feature map, mỗi ô được gọi là một cell và từ tâm của mỗi cell xác định một tợp hợp các boxes mặc định (default boxes) để dự đoán khung hình có khả năng bao quanh vật thể. Tại thời điểm dự báo, mạng neural sẽ trả về 2 giá trị đó là: phân phối xác suất nhãn của vật thể chứa trong bounding box và một tọa độ gọi là offsets của bounding box. Quá trình huấn luyện cũng là quá trình tinh chỉnh xác suất nhãn và bounding box về đúng với các giá trị ground truth input của mô hình (gồm nhãn và offsets bounding box).
Thêm nữa, network được kết hợp bởi rất nhiều các feature map với những độ phân giải khác nhau giúp phát hiện được những vật thể đa dạng các kích thước và hình dạng. Trái với mô hình fast R-CNN, SSD bỏ qua bước tạo mặt nạ region proposal network để đề xuất vùng vật thể. Thay vào đó tất cả quá trình phát hiện vật thể và phân loại vật thể được thực hiện trong cùng 1 mạng. Bản thân tên của mô hình - Single Shot MultiBox Detector cũng nói lên được rằng mô hình sử dụng nhiều khung hình box với tỷ lệ scales khác nhau nhằm nhận diện vùng vật thể và phân loại vật thể, giảm thiểu được bước tạo region proposal network so với fast R-CNN nên tăng tốc độ xử lý lên nhiều lần mà tốc độ xử lý vẫn đảm bảo
4. Yolo (You Only Look Once)
4.1. YOLO v1 (2015)
Mô hình YOLO được mô tả lần đầu tiên bởi Joseph Redmon, và các cộng sự. trong bài viết năm 2015 có tiêu đề Bạn chỉ nhìn một lần: Phát hiện đối tượng theo thời gian thực - (You Only Look Once: Unified, Real-Time Object Detection)[https://arxiv.org/abs/1506.02640]. Trong công trình này thì một lần nữa Ross Girshick, người phát triển mạng R-CNN, cũng là một tác giả và người đóng góp khi ông chuyển qua (Facebook AI Research)[https://research.fb.com/category/facebook-ai-research/].
Phương pháp chính dựa trên một mạng neural network duy nhất được huấn luyện dạng end-to-end model. Mô hình lấy input là một bức ảnh và dự đoán các bounding box và nhãn lớp cho mỗi bounding box. Do không sử dụng region proposal nên kỹ thuật này có độ chính xác thấp hơn (ví dụ: nhiều lỗi định vị vật thể - localization error hơn), mặc dù hoạt động ở tốc độ 45 fps (khung hình / giây) và tối đa 155 fps cho phiên bản tối ưu hóa tốc độ. Tốc độ này còn nhanh hơn cả tốc độ khung hình của máy quay phim thông thường chỉ vào khoảng 24 fps.
Mô hình hoạt động bằng cách trước tiên phân chia hình ảnh đầu vào thành một lưới các ô (grid of cells), trong đó mỗi ô chịu trách nhiệm dự đoán các bounding boxes nếu tâm của nó nằm trong ô. Mỗi grid cell (tức 1 ô bất kì nằm trong lưới ô) dự đoán các bounding boxes được xác định dựa trên tọa độ x, y (thông thường là tọa độ tâm, một số phiên bản là tọa độ góc trên cùng bên trái) và chiều rộng (width) và chiều cao (height) và độ tin cậy (confidence) về khả năng chứa vật thể bên trong. Ngoài ra các dự đoán nhãn cũng được thực hiện trên mỗi một bonding box.
Ví dụ: một hình ảnh có thể được chia thành lưới 7 × 7 và mỗi ô trong lưới có thể dự đoán 2 bounding box, kết quả trả về 98 bounding box được đề xuất. Sau đó, một sơ đồ xác suất nhãn (gọi là class probability map) với các confidence được kết hợp thành một tợp hợp bounding box cuối cùng và các nhãn. Hình ảnh được lấy từ bài báo dưới đây tóm tắt hai kết quả đầu ra của mô hình.
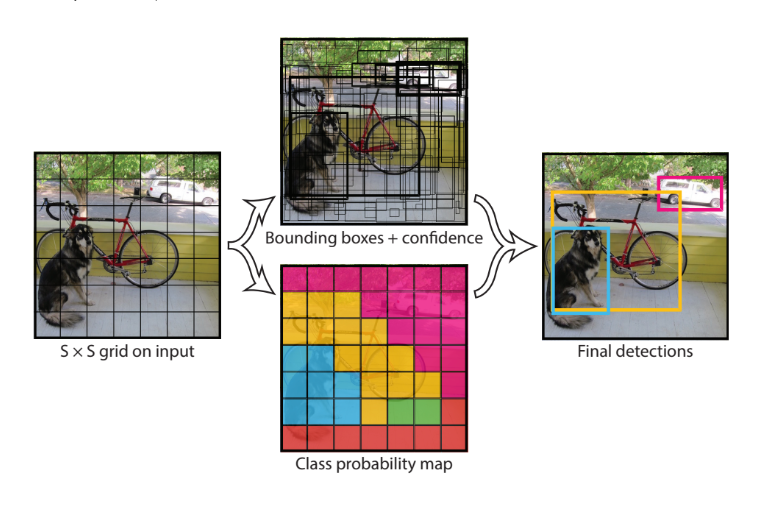
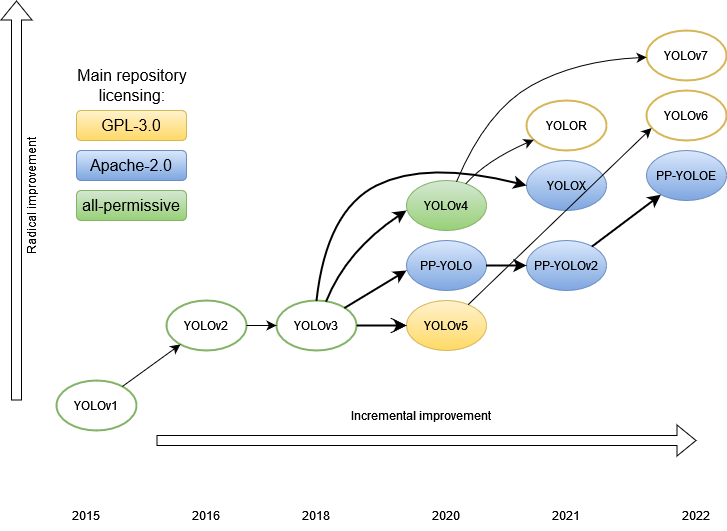
Mô hình YOLO đã trải qua nhiều cải tiến và thay đổi từ YOLO v1 cho tới YOLO v7 (2022) cũng như xuất hiện nhiều biển thể của nó: YOLOF, YOLOR, YOLOS, YOLOX, YOLOP…:D và đây đều là những the-state-of-the-art model hiện nay nên để hiểu hết họ hàng của YOLO thì bạn cũng phải đầu tư nhiều thời gian :D. Bài viết này chỉ mang tính chất giới thiệu về các hướng đi hiện có cho bài toán Object Detection nên việc đi sâu vào các mô hình sẽ không được đề cập - chi tiết ở các bài viết tiếp theo.
5. Tổng kết
Trong bài viết này chúng ta đã tìm hiểu một cách khái quát các khái niệm cơ bản trong computer vision và lịch sử hình thành, phát triển của các lớp mô hình ứng dụng trong object detection. Mình xin tổng kết lại:
Phân biệt các khái niệm về image classification, object localization, object detection.
Họ các mô hình object detection dựa trên Region-Based Convolutional Neural Network (R-CNNs) gồm các lớp mô hình: R-CNN, Fast R-CNN và Faster R-CNN là những mô hình sơ khai, có tốc độ xử lý chậm. Thuật toán dựa trên 2 phần xử lý riêng biệt là phát hiện các region proposal và phân loại hình ảnh.
Lớp các mô hình SSD hay YOLO có tốc độ thời gian xử lý thực. Là công nghệ state-of-art nhất hiện nay có tốc độ xử lý realtime, phát hiện được lên tới 9000 loại đối tượng.
Nhìn chung, các kiến trúc object detection đều dựa trên một deep CNN network chẳng hạn như VGG16 hoặc Alexnet ở giai đoạn đầu giúp trích lọc features và nhận diện các region proposal. Sau đó phát triển thuật toán nhằm tìm ra bounding box và confidence của đối tượng chứa trong bounding box. Tùy vào thiết kế mà các mô hình có thể theo dạng pipeline hoặc trong một single model. Tốc độ xử lý của mô hình phụ thuộc vào số lượng bounding box mà nó tạo ra.
