

Post 5 - [YOLO Series] YOLO You Only Look Once
“The secret of getting ahead is to get started.” – Mark Twain

1. Giới thiệu
Như ở Post 4 - Object Detection Overview ta đã làm quen với bài toán Object Detection cũng như các phương pháp SOTA (State-of-the-art) cho bài toán. Thì trong bài post này ta sẽ đi sâu vô một phương pháp nổi tiếng và được sử dụng rộng rãi cho tới thời điểm hiện tại là YOLO (You Only Look Once).
YOLO như tên gọi của nó - You Only Look Once ccó nghĩa là một thuật toán phát hiện tất cả đối tượng trong 1 hình ảnh/khung hình(frame) chỉ cần 1 lần tìm kiếm. Rất nhanh và mạnh phải không nào?:D Thật vậy, về độ chính xác thì YOLO có thể không phải là thuật toán tốt nhất nhưng nó là thuật toán nhanh nhất trong các lớp mô hình object detection. Nó có thể đạt được tốc độ gần như real time mà độ chính xác không quá giảm so với các model thuộc top đầu.
YOLO là thuật toán object detection nên mục tiêu của mô hình không chỉ là dự báo nhãn cho vật thể như các bài toán classification mà nó còn xác định location của vật thể. Do đó YOLO có thể phát hiện được nhiều vật thể có nhãn khác nhau trong một bức ảnh thay vì chỉ phân loại duy nhất một nhãn cho một bức ảnh.
Giờ ta sẽ đi sâu vô từng phiên bản của nó và cách nó hoạt động cũng như cuộc cách mạng YOLO phát triển như thế nào cho tơi thời điểm hiện tại :D.
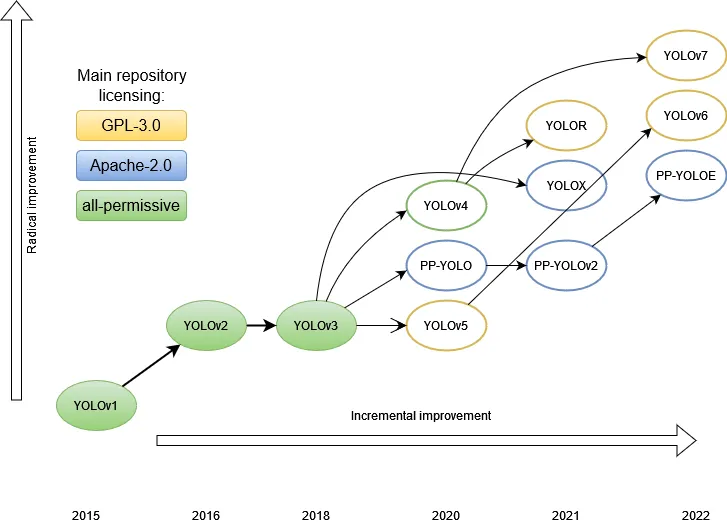
Trước tiên thì phải nói sơ qua sự phát triển mạnh mẽ của YOLO theo thời gian. Với sự ra mắt lần đầu tiên vào năm 2015 với phiên bản YOLO v1 bởi Joseph Redmon, và các cộng sự. trong bài viết năm 2015 có tiêu đề Bạn chỉ nhìn một lần: Phát hiện đối tượng theo thời gian thực - You Only Look Once: Unified, Real-Time Object Detection. Trong công trình này thì một lần nữa Ross Girshick, người phát triển mạng R-CNN, cũng là một tác giả và người đóng góp khi ông chuyển qua Facebook AI Research. Tiếp sau đó là liên tục những phiên bản mới YOLO v2/YOLO 9000,… cho tới YOLO v7 như hiện nay được thay đổi và phát triển bởi nhóm tác giả bạn đầu và những biến thể khác: YOLOX, YOLOR,… bởi các nhà nghiên cứu khác. Bài viết này mình chỉ đi sâu và nói về các phiên bản chính của YOLO (Từ v1 đến v7), các biến thế khác nếu có thời gian mình sẽ lên bài thêm sau.
Thuật ngữ
Ta sẽ điểm qua các thuật ngữ, khái niệm trước khi tìm hiểu YOLO:
- Mạng nơ ron tích chập (Convolutional Neural Network): Đây là mạng nơ ron áp dụng các layer Convolutional kết hợp với Maxpooling để giúp trích xuất đặc trưng của ảnh tốt hơn.
- Khái niệm về bounding box, anchor box: Bounding box là khung hình bao quanh vật thể. Anchor box là những khung hình có kích thước xác định trước, có tác dụng dự đoán bounding box.
- Feature map: Là một khối output mà ta sẽ chia nó thành một lưới ô vuông và áp dụng tìm kiếm và phát hiện vật thể trên từng cell.
- IoU (intersection over union) là độ đo đánh giá các mô hình nhận diện thực thể. Phép đo này có thể đánh giá các mô hình khác nhau như RCNN, Fast-RCNN, Faster- RCNN hay YOLO. IoU = Diện tích phần GIAO /Diện tích phần HỢP
- Non-max suppression: Phương pháp giúp giảm thiểu nhiều bounding box overlap nhau về 1 bounding box có xác suất lớn nhất.
- Ground Truth: một thuật ngữ thường được sử dụng trong thống kê và học máy. Nó đề cập đến câu trả lời đúng hoặc “đúng” cho một vấn đề hoặc câu hỏi cụ thể. Nó là một “tiêu chuẩn vàng” có thể được sử dụng để so sánh và đánh giá kết quả mô hình. Ví dụ: trong bài toán phát hiện vật thể, ground truth là nhãn của vật thể và vị trí của bounding box.
- Mạng backbone: là một mạng neural network lớn và sâu được sử dụng để rút trích các đặc trưng chung và trừu tượng từ dữ liệu đầu vào. Nó là phần của mô hình được huấn luyện trước, thường được sử dụng trong các tác vụ như phân loại ảnh, nhận dạng vật thể và xử lý ngôn ngữ tự nhiên. Mạng backbone thường được sử dụng là mạng ResNet, VGG, MobileNet, EfficientNet, Darknet, …
2. YOLO v1 (2015)
Trước khi YOLO ra đời, cách tiếp cận chính cho bài toán Object Detection là sử dụng các cửa số trượt (sliding windows) như RCNN sử dụng Region Proposal Networks (RPNs) với nhiều kích thước khác nhau (ta đã đề cập ở Post 4 sau đó tuần tự trượt qua ảnh gốc để tạo các bounding box. Sau đó chạy qua bộ phân loại (classifier) và xử lý các bounding box để lọc ra những bounding box có khả năng cao là vật thể. Các giai đoạn riêng lẻ của mạng R-CNN phải được đào tạo riêng. Cách tiếp cận hợp lý nhưng điều này làm cho thuật toán chậm và không thể thực hiện được trong thời gian thực.
Một thời gian sau, sự nâng cấp phiên bản của RCNN đề tập tới khái niệm mới là RoI (regions of interest) được gọi là layer vùng quan tâm nhưng ta vẫn còn hàng ngàn features map cần quan tâm. Thuật toán nhanh nhất, Faster R-CNN, xử lý một hình ảnh trên thiết bị trung bình trong 0,2 giây, mang lại cho chúng ta 5 khung hình mỗi giây (5 frames/s).
Vậy điểm mới trong YOLO là gì?
Trong các phương pháp trước đây, mỗi pixel của hình ảnh gốc có thể được xử lý bởi mạng neural vài trăm hoặc thậm chí hàng nghìn lần. Và mỗi lần như thế thì những pixel này được truyền qua cùng một mạng neural, trải qua các phép tính giống nhau. Có thể làm điều gì đó để không lặp lại các phép tính tương tự không?
2.1. Kiến trúc mạng YOLO v1
Kiến trúc YOLO bao gồm:
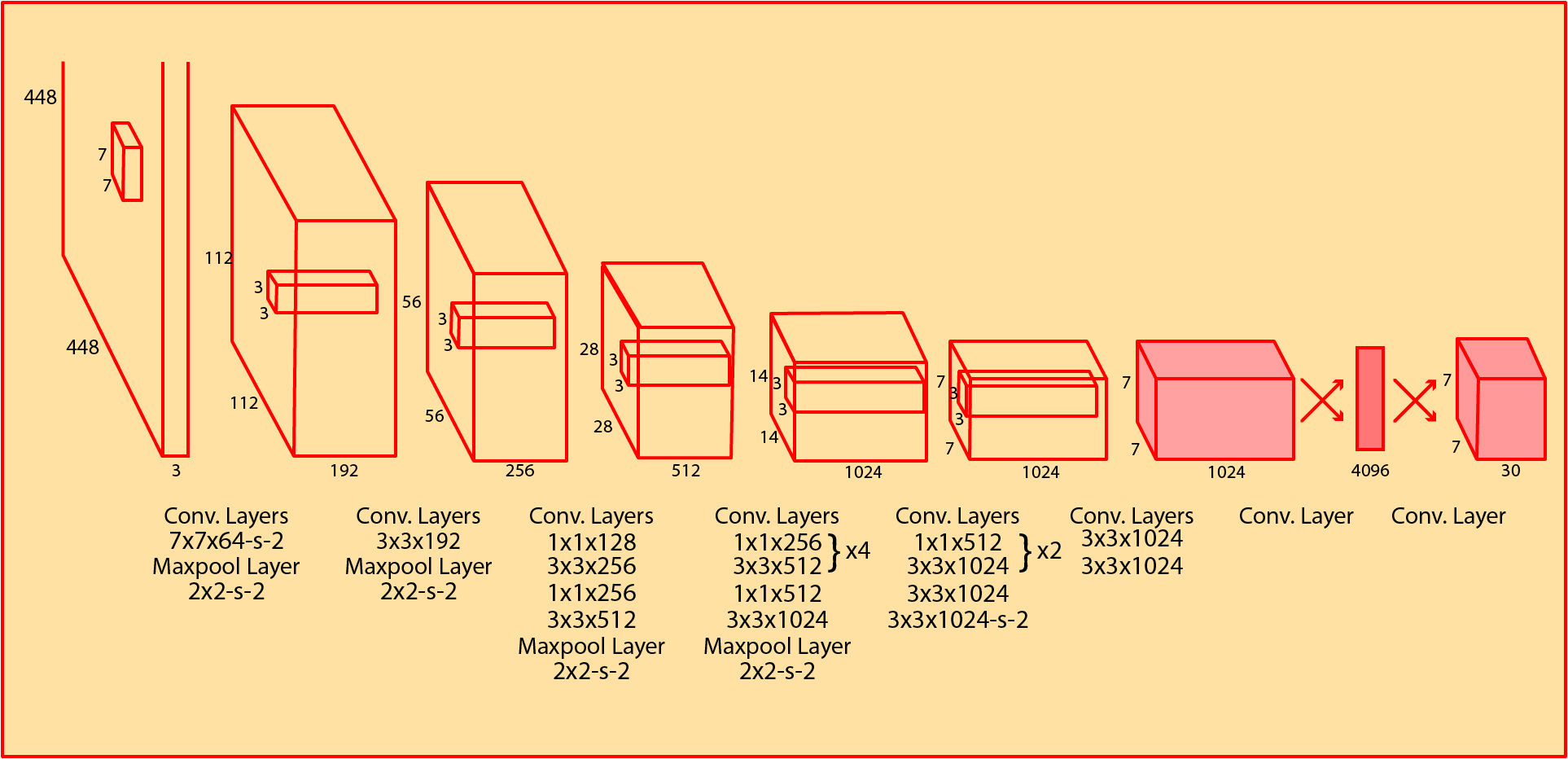
- Thành phần Darknet Architechture là các mạng convolution được gọi là base network có tác dụng trích suất đặc trưng. Base network của YOLO sử dụng chủ yếu là các convolutional layer và các fully conntected layer. Các kiến trúc YOLO cũng khá đa dạng và có thể tùy biến thành các version cho nhiều input shape khác nhau.
- Output của base network là một feature map có kích thước 7x7x1024 sẽ được sử dụng làm input cho các Extra layers có tác dụng dự đoán nhãn và tọa độ bounding box của vật thể.
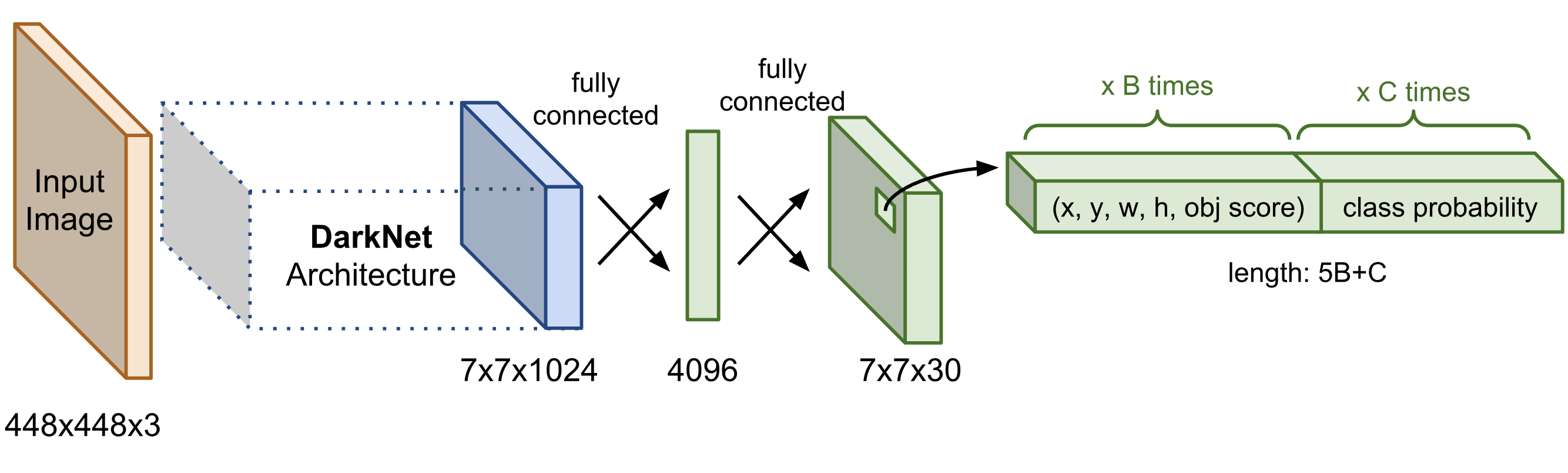
Từ input là ảnh đầu vào, qua một mạng gồm các lớp convolution, pooling và fully connected là có thể ra được output. Kiến trúc này có thể được tối ưu để chạy trên GPU với một lần forward pass, và vì thế đạt được tốc độ rất cao.
2.2. Ý tưởng chính
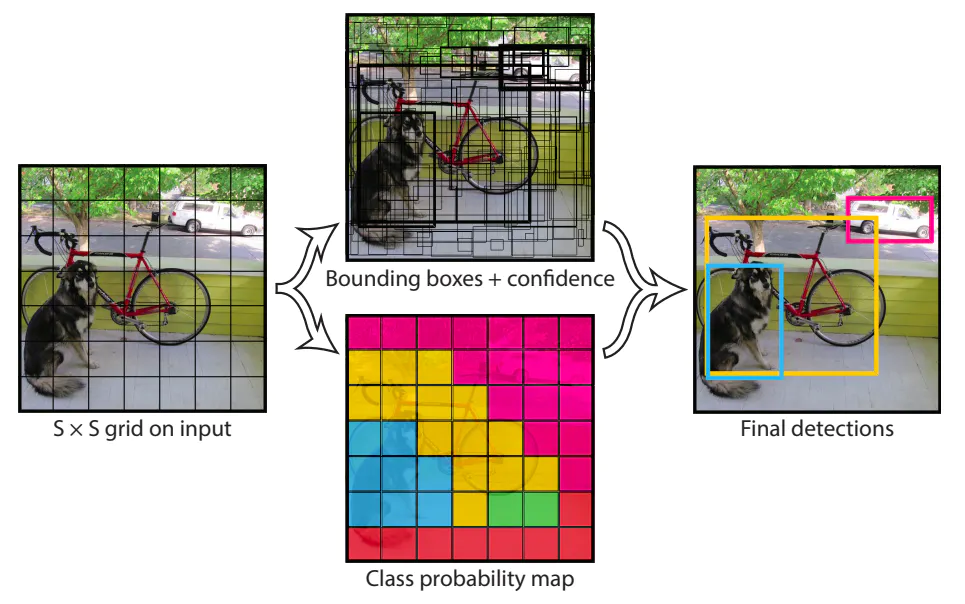
Ý tưởng chính của YOLOv1 là chia ảnh thành một lưới các ô (grid cell) với kích thước SxS (mặc định là 7x7). Với mỗi grid cell, mô hình sẽ đưa ra dự đoán cho B bounding box. Ứng với mỗi box trong B bounding box này sẽ là 5 tham số x, y, w, h, confidence, lần lượt là tọa độ tâm (x, y), chiều rộng w, chiều cao h và độ tự tin của dự đoán. Với grid cell trong lưới SxS kia, mô hình cũng dự đoán xác suất rơi vào mỗi class.
Độ tự tin của dự đoán ứng với mỗi bounding box được định nghĩa là \(p(Object) * IOU^{truth}_{pred}\) ,trong đó \(p(Object)\) là xác suất có vật trong cell và \(IOU_{pred.}^{truth}\) là intersection over union của vùng dự đoán và ground truth.
Xác suất rơi vào mỗi class cho một grid cell được ký hiệu \(p(Class_i∣Object)\). Các giá trị xác suất cho C class sẽ tạo ra C output cho mỗi grid cell. Lưu ý là B bounding box của cùng một grid cell sẽ chia sẻ chung một tập các dự đoán về class của vật, đồng nghĩa với việc tất cả các bounding box trong cùng một grid cell sẽ chỉ có chung một class.
Vậy tổng số output của mô hình sẽ là \(S×S×(5∗B+C)\) (dưới dạng matrix). Hình dưới đây là kiến trúc của YOLOv1. Mạng backbone của YOLOv1 lấy ý tưởng từ kiến trúc GoogleNet.
Như vậy, bạn đã thấy rằng YOLO tính toán tọa độ bbox, xác suất có xuất hiện vật thể, phân bố xác suất để phân loại vật thể… tất cả đều được thực hiện trong 1 lần. Đó là lý do khiến cho YOLO nhanh hơn nhiều so với các 2-stage model, tạo nên lợi thế cho YOLO.
2.3 Loss function
Cũng tương tự như SSD, hàm loss function của YOLO chia thành 2 phần:
- $L_{loc}$ (localization loss) đo lường sai số của bounding box
- &L_{cls}& (confidence loss) đo lường sai số của phân phối xác suất các classes
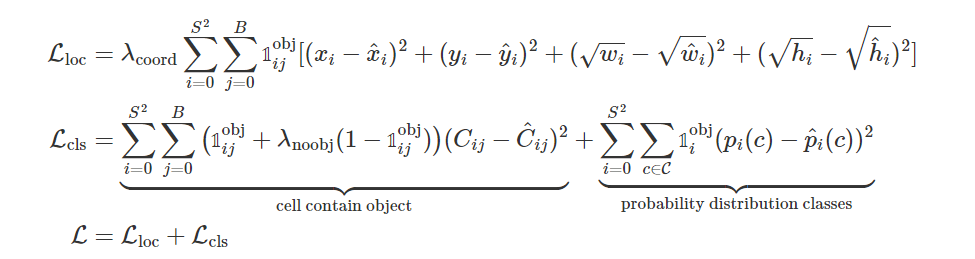
Trong đó:
- $1_{ij}^{obj}$ là hàm indicator có giá trị 0, 1 , \(1_{ij}^{obj} = 1\) nếu cell \(i\) chứa object và \(1_{ij}^{obj} = 0\) nếu không chứa object.
- $1_{i}^{obj}$ xác định xem cell i có chứa vật thể hay không. Bằng 1 nếu chứa vật thể và 0 nếu không chứa.
- $1_{i}^{noobj}$ ngược lại với \(1_{i}^{obj}\).
- $\lambda_{coord}$ và $\lambda_{noobj}$ là hệ số điều chỉnh.
- $C_{ij}$ là điểm tin cậy của bouding box \(i\) trong cell \(j\) = $p(Object) * IOU^{truth}_{pred}$
- $\hat{C}_{ij}$ là điểm tin cậy dự đoán của bounding box \(i\) trong cell \(j\)
- $C$ là số lượng class
- $p_{ij}$ là xác suất có vật thể trong cell $i$
- $\hat{p}_{ij}$ là xác suất dự đoán có vật thể trong cell $i$
2.4 Non Max Suppression
Giả sử trải qua quá trình huấn luyện mô hình, bạn thu được một model đủ tốt và muốn đưa vào ứng dụng. Tuy nhiên model dù tốt vẫn xảy ra trường hợp: dự đoán nhiều bounding box cho cùng một vật thể.

Để giải quyết vấn đề này, ta lọc bớt các bouding box dư thừa ( trùng nhau và cùng class) bằng non-max suppression. Ý tưởng:
- Các box có confidence_score được xếp hạng từ cao xuống thấp. $[box_0, box_1, … box_n]$ Duyệt từ đầu danh sách, với từng $box_i$, loại đi các $box_j$ có $IOU(box_i, box_j) > threshold$. Trong đó $j > i$. threshold là một giá trị ngưỡng được lựa chọn sẵn. IOU là công thức tính độ overlap - giao thoa giữa hai bounding box.
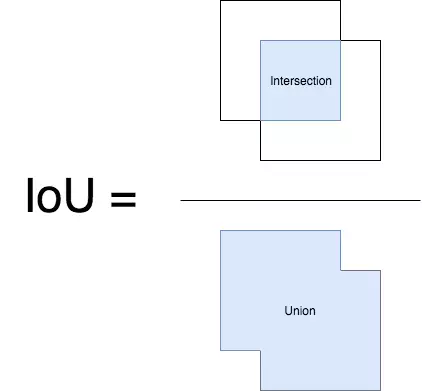
Nếu chỉ số này lớn hơn ngưỡng threshold thì điều đó chứng tỏ 2 bounding boxes đang overlap nhau rất cao. Ta sẽ xóa các bounding có có xác xuất thấp hơn và giữ lại bouding box có xác xuất cao nhất. Cuối cùng, ta thu được một bounding box duy nhất cho một vật thể.
2.5 Nhược điểm của YOLOv1
- Độ chính xác vẫn còn kém so với các Region-based detector.
- YOLOv1 áp đặt các ràng buộc về không gian trên những bounding box, mỗi grid cell chỉ có thể predict rất ít bounding box (B) và duy nhất một class. Điều đó có nghĩa rằng nếu ta chọn S x S = 7 x 7, số lượng object tối đa chỉ bằng 49. Các ràng buộc này hạn chế khả năng nhận biết số object nằm gần nhau, cũng như đối với các object có kích thước nhỏ.
- (x,y,w,h) được predict ra trực tiếp -> giá trị tự do. Trong khi đó trong hầu hết các dataset, các bouding box có kích cỡ không quá đa dạng mà tuân theo những tỷ lệ nhất định.
- Ngoài ra, trong quá trình training, loss function không có sự đánh giá riêng biệt giữa error của bounding box kích thước nhỏ so với error của bounding box kích thước lớn. Việc coi chúng như cùng loại và tổng hợp lại làm ảnh hưởng đến độ chính xác toàn cục của mạng. Error nhỏ trên box lớn nhìn chung ít tác hại, nhưng error nhỏ với box rất nhỏ sẽ đặc biệt ảnh hưởng đến giá trị IOU.
3. YOLO v2 (2016)
YOLOv2 đặt tên là YOLO9000 (có khả năng dự đoán lên tới 9000 loại đối tượng khác nhau) đã được Joseph Redmon và Ali Farhadi công bố vào cuối năm 2016 và có mặt trong 2017 CVPR. Cải tiến chính của phiên bản này tốt hơn, nhanh hơn, tiên tiến hơn để bắt kịp faster R-CNN (phương pháp sử dụng Region Proposal Network), xử lý được những vấn đề gặp phải của YOLOv1.
3.1 Thêm Batch Normalization
Kĩ thuật Batch Normalization được đưa vào sau tất cả các lớp convolution của YOLOv2. Kĩ thuật này không những giảm được thời gian huấn luyện, mà còn có tác dụng tăng tính phổ quát (generalize) cho mạng. Ở YOLOv2, Batch Normalization giúp tăng mAP lên khoảng 2%. Mạng cũng không cần sử dụng thêm Dropout để tăng tính phổ quát.
3.2 High resolution classifier
YOLO được huấn luyện với 2 pha. Pha đầu sẽ huấn luyện một mạng classifier với ảnh đầu vào kích thước nhỏ (224x224) và pha sau sẽ loại bỏ lớp fully connected và sử dụng mạng classifier này như phần khung xương (backbone) để huấn luyện mạng detection. Lưu ý rằng ảnh đầu vào kích thước nhỏ cũng thường được sử dụng để huấn luyện các mạng classifier, mà sau đó sẽ được sử dụng như pretrained model cho phần backbone của các mạng detection khác. Ở pha sau YOLO trước hết finetune mạng backbone dưới ảnh đầu vào kích thước lớn hơn là 448x448, để mạng “quen” dần với kích thước ảnh đầu vào lớn, sau đó mới sử dụng kết quả này để huấn luyện 10 epochs trên ImageNet cho quá trình detection. Điều này giúp tăng mAP của YOLOv2 lên khoảng 4%.
3.3 Sử dụng kiến trúc anchorbox để đưa ra dự đoán
Thực ra anchor box là ý tưởng của FasterRCNN. Như đã nói, người ta nhận thấy rằng trong hầu hết các bộ dataset, các bbox thường có hình dạng tuân theo những tỷ lệ và kích cỡ nhất định.
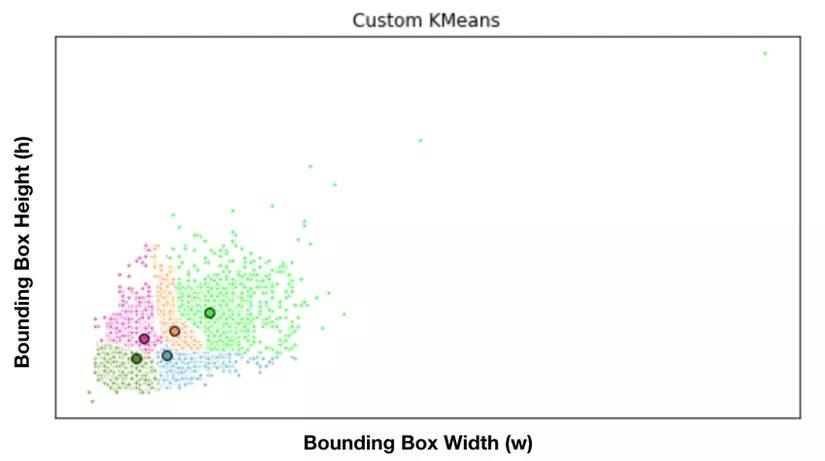
Bằng việc dùng Kmean để phân cụm, ta sẽ tính ra được B anchor box đại diện cho các kích thước phổ biến. Dưới đây là minh họa cho cách tính các anchor box đại diện trong 1 bộ dataset.
Trong YOLOv2, tác giả loại bỏ lớp fully connected ở giữa mạng và sử dụng kiến trúc anchorbox để predict các bounding box. Việc dự đoán các offset so với anchorbox sẽ dễ dàng hơn nhiều so với dự đoán toạ độ bounding box. Thay đổi này làm giảm mAP đi một chút nhưng làm recall tăng lên.
3.4 K-mean clustering cho lựa chọn anchor
Thay vì phải chọn anchorbox bằng tay, YOLOv2 sử dụng thuật toán k-means để đưa ra các lựa chọn anchorbox tốt nhất cho mạng. Việc này tạo ra mean IoU tốt hơn.
3.5 Direct location prediction
YOLOv1 không có các hạn chế trong việc dự đoán vị trí của bounding box. Khi các trọng số được khởi tạo ngẫu nhiên, bounding box có thể được dự đoán ở bất kỳ đâu trong ảnh. Điều này khiến mô hình không ổn định trong giai đoạn đầu của quá trình huấn luyện. Vị trí của bounding box có thể ở rất xa so với vị trí của grid cell.
YOLOv2 sử dụng hàm sigmoid (σ) để hạn chế giá trị trong khoảng 0 đến 1, từ đó có thể hạn chế các dự đoán bounding box ở xung quanh grid cell, từ đó giúp mô hình ổn định hơn trong quá trình huấn luyện. YOLOv2 đã có thêm 5% mAP khi áp dụng phương pháp này.
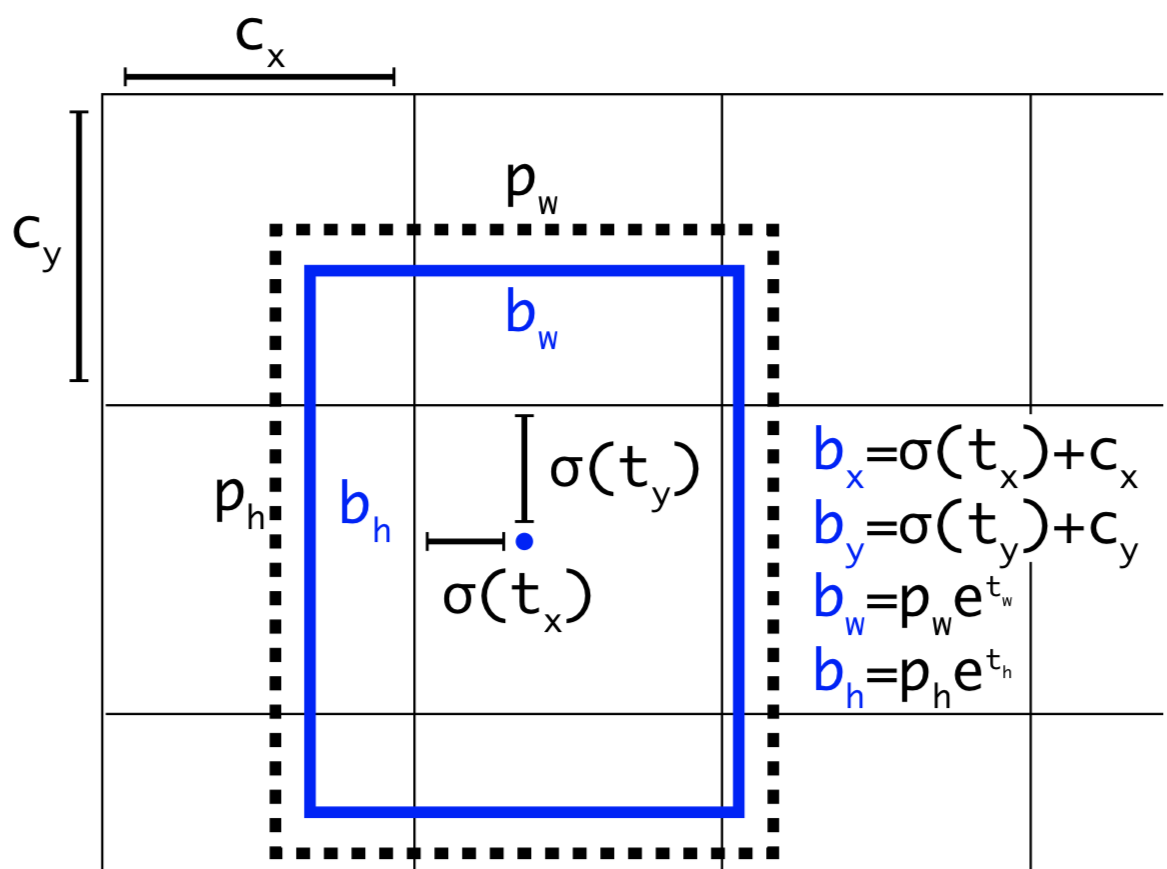
Cho anchorbox có kích thước \((p_w, p_h)\) nằm tại grid cell với vị trí top left là \((c_x, c_y)\) , mô hình sẽ dự đoán các offset và scale $t_x, t_y, t_w, t_h$ và bounding box dự đoán có tâm là $(b_x, b_y)$ và kích thước $(b_w, b_h)$ thông qua hàm sigmoid và hàm exponential như các công thức bên dưới. Độ tự tin (confidence của dự đoán là $σ(t_0))$.
\[b_x = σ(t_x) + c_x, b_y = σ(t_y) + c_y, b_w = p_w e^{t_w}, b_h = p_h e^{t_h}\] \[Pr(Object) . IoU(b, object) = σ(t_0)\]Ngoài ra do các tọa độ đã được hiệu chỉnh theo width và height của bức ảnh nên luôn có giá trị nằm trong ngưỡng [0, 1]. Do đó khi áp dụng hàm sigmoid giúp ta giới hạn được tọa độ không vượt quá xa các ngưỡng này.
3.6 Add fine-grained features
YOLOv2 sử dụng feature map 13x13 để đưa ra các dự đoán, lớn hơn 7x7 của YOLOv1.
Faster R-CNN và SSD đưa ra dự đoán ở nhiều tầng khác nhau trong mạng để tận dụng các feature map ở các kích thước khác nhau. YOLOv2 cũng kết hợp các feature ở các tầng khác nhau lại để đưa ra dự đoán, cụ thể kiến trúc nguyên bản của YOLOv2 kết hợp feature map 26x26 lấy từ đoạn gần cuối với feature map 13x13 ở cuối để đưa ra các dự đoán. Cụ thể là các feature map này sẽ được ghép vào nhau (concatenate) để tạo thành một khối sử dụng cho dự đoán.
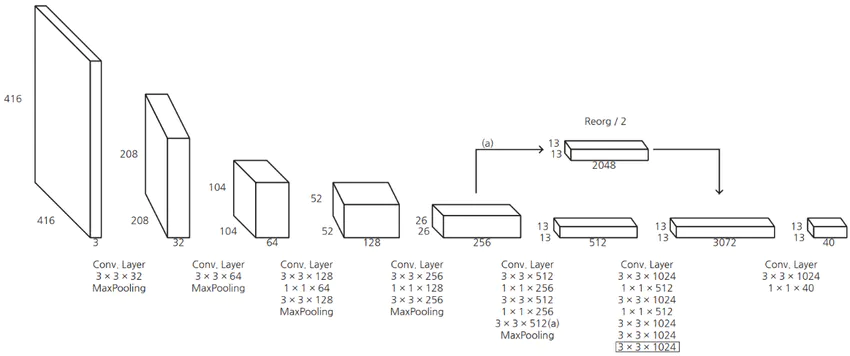
Vậy làm thế nào để concatenate được 2 feature map kích thước 26 x 26 x m và 13 x 13 x n để trở thành một feature map 13 x 13 x p ?
Thông thường việc concatenate 2 feature map chỉ thực hiện được khi chúng có cùng chiều rộng và chiều dài. Tuy nhiên trong YOLOv2 tác giả sử dụng lớp Reorg, tuy nhiên lại không mô tả kỹ về kĩ thuật này trong paper. Thực ra Reorg chỉ là kĩ thuật tổ chức lại bộ nhớ để biến feature map 26x26 thành 13x13 với chiều sâu lớn hơn để có thể thực hiện phép concatenate với feature map 13x13 ở cuối.
Trong trường hợp tổng quát của phép Reorg, ta sẽ biến feature map kích thước $[N,C,H,W]$ thành kích thước $[N,C \cdot s^2,\frac{H}{2}, \frac{W}{2}]$, tức là số lượng tham số trong feature map vẫn được giữ nguyên. Khi ta muốn giảm kích thước dài, rộng đi mỗi cạnh 2 lần thì số channel phải được tăng lên 4 lần. Việc biến đổi này hoàn toàn không giống phép resize trong xử lý ảnh. Để dễ hình dung, bạn có thể xem hình vẽ dưới đây:
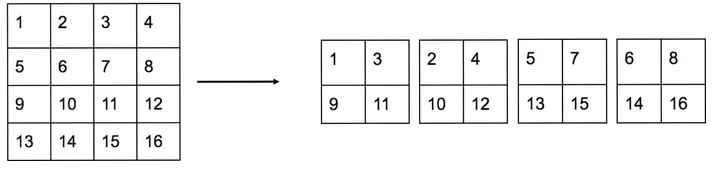
Đây là một lát cắt (channel) của feature map kích thước 4x4. Để đưa về kích thước 2x2, tức là giảm chiều rộng đi 2 lần và chiều dài đi 2 lần, ta tách channel của feature map 4x4 thành 4 ma trận như hình trên, ứng với 4 channel chiều sâu của feature map 2x2 mới. Vị trí các giá trị trong mỗi channel của feature map 2x2 mới sẽ lấy thưa thớt trên feature map 4x4 ban đầu với stride = 2 theo 2 trục dài và rộng.
Bạn đọc có thể tìm hiểu chi tiết về Reorg trong YOLOv2, bao gồm cả code về kỹ thuật Reorg, tại blog của Lei Mao. Bằng kĩ thuật “Add fine-grained features”, performance của mạng YOLOv2 được tăng thêm 1%.
3.7 Add multi-scale training
Sau khi thêm kĩ thuật anchorbox cho YOLOv2, tác giả đã thay đổi input của mạng thành 416x416 thay vì 448x448. Tuy vậy, YOLOv2 được thiết kể chỉ gồm các lớp convolution và pooling nên có thể thích ứng với nhiều kích thước ảnh đầu vào khác nhau. Tác giả đã huấn luyện mạng trên nhiều kích thước ảnh khác nhau để tăng khả năng thích ứng của YOLOv2 với đa dạng kích thước ảnh.
3.8 Light weight backbone
Điểm cải tiến của YOLOv2 còn phải kể đến backbone mới có tên Darknet-19. Mạng này bao gồm 19 lớp convolution và 5 lớp maxpooling tạo ra tốc độ nhanh hơn phiên bản YOLO trước.
YOLOv2 cũng là cơ sở của mô hình YOLO9000 có khả năng phát hiện hơn 9000 lớp trong thời gian thực.
3.9 Loss function
Loss function, về cơ bản, loss function của YOLO v2 vẫn như vậy, khi code chỉ cần khéo léo khi tính $(b_x, b_y, b_w, b_h).$
3.9 YOLO9000
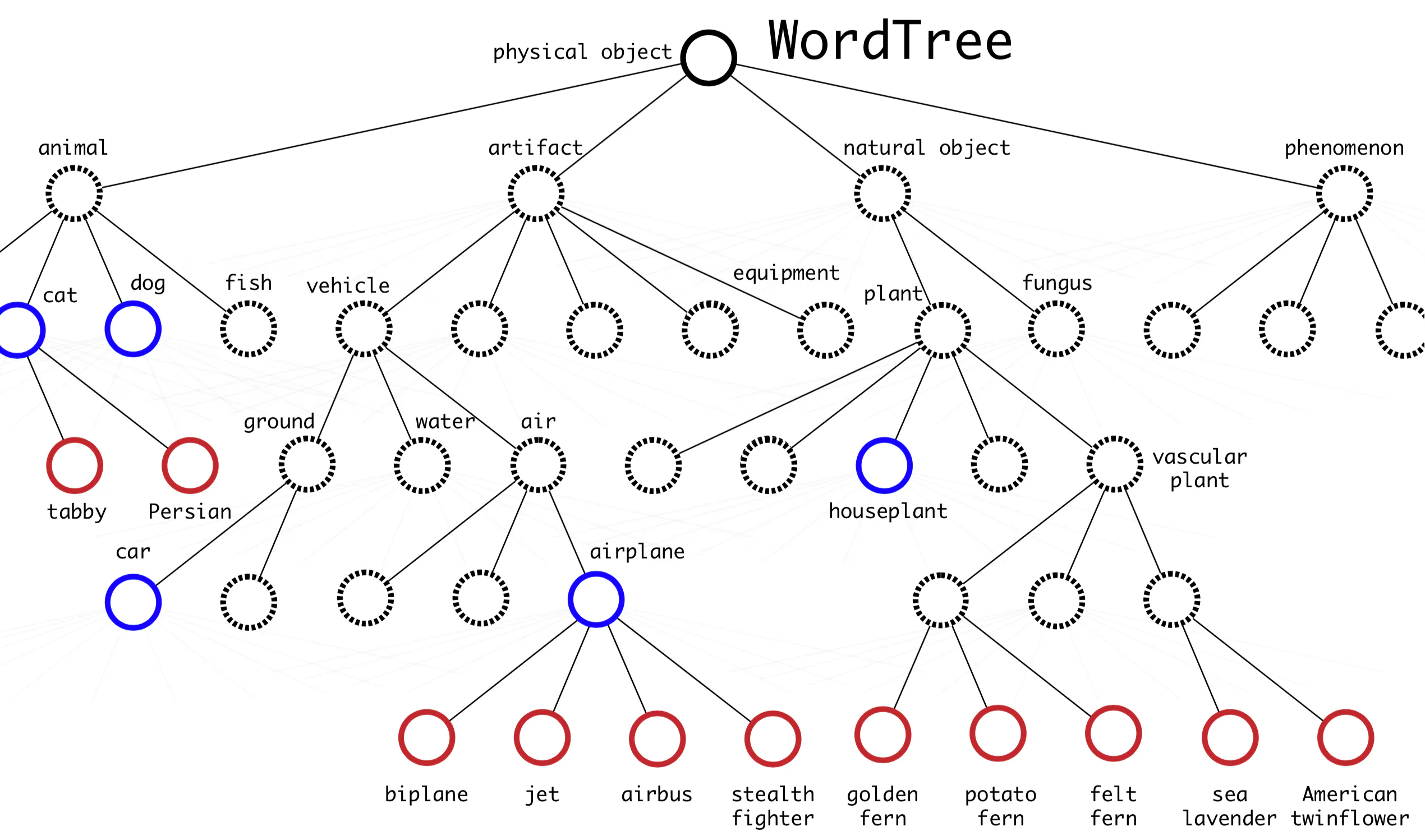
YOLO9000 đưa ra cách kết hợp các dataset khác với ImageNet để có thể phát hiện nhiều class hơn. Tác giả tạo một directed graph gọi là WordTree như hình dưới. Để có thể merge được các label từ tập ImageNet (1000 class) với COCO/PASCAL (100 class), tác giả dựa vào WordNet để xây dựng quan hệ giữa các class, từ đó có thể huấn luyện mạng nhận dạng các class có quan hệ với nhau.
4. YOLO v3 (2018)
YOLO đã trở nên rất nổi tiếng cho bài toán phát hiện vật thể thời gian thực. Tuy nhiên kể từ phiên bản YOLOv3, tác giả đầu tiên của YOLO là Joseph Redmon đã không còn nghiên cứu và cải thiện kiến trúc này nữa. Anh còn tuyên bố đã ngừng nghiên cứu về thị giác máy tính do các lo ngại công nghệ được sử dụng sai mục đích (sử dụng cho quân sự, các lo ngại về quyền riêng tư). Tuy thế, trên quan điểm của tôi, công nghệ luôn có 2 mặt, tốt và xấu. Chúng ta vẫn sẽ nhận được các “bản nâng cấp” YOLO từ các tác giả khác, như YOLOv4, YOLOv5 và cho tới YOLOv7 tại thời điểm mình viết bài này :D.
“I stopped doing CV research because I saw the impact my work was having. I loved the work but the military applications and privacy concerns eventually became impossible to ignore.” - Joseph Redmon
5. YOLO v4 (2020)
6. YOLO v5 (2021)
7. YOLO v6 (2022)
8. YOLO v7 (2022)
8. YOLO v8 (2023)
9 Các biển thể khác của YOLO
6. References
- [1] YOLO: Real-Time Object Detection
- [2] You Only Look Once: Unified, Real-Time Object Detection
- [3] The The evolution of the YOLO neural networks family from v1 to v7 - Medium
- [4] Bài 25 - YOLO You Only Look Once - phamdinhkhanhblog
- [5] YOLO v2 – Object Detection - Geeksforgeeks
- [6] YOLO9000: Better, Faster, Stronger - Joseph Redmon, Ali Farhadi
- [7] Tìm hiểu mô hình YOLO cho phát hiện vật - Từ YOLOv1 đến YOLOv3
